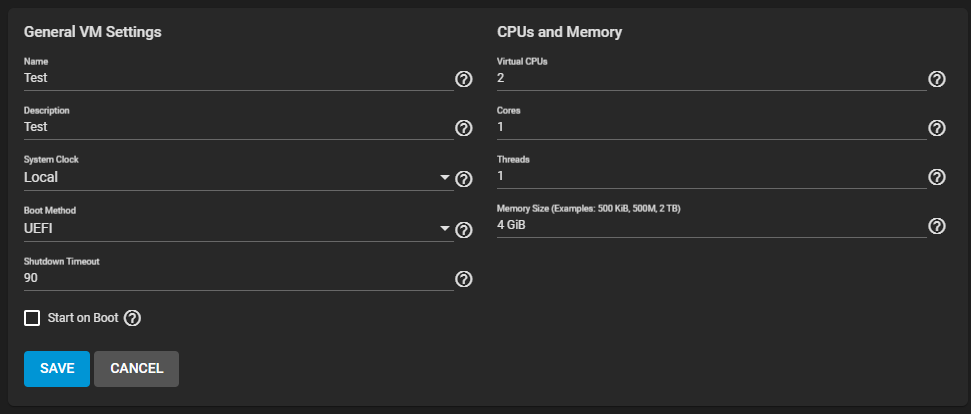
La ARC dove la metti ? Di 16GB: 8 Se li prende la ARC e circa 3 il TN infine lasciane circa 1GB "di scorta" = 16 -8 -3 -1 GB = 4GB disponibili per docker/vm/jail. In pratica 1VM con 4GB di ram, Io con quel quantitativo faccio girare 5 Docker (3 "Low power")
Io eviterei di comprimere la ARC con così poca ram ma lasciargli tutto lo spazio disponibile.
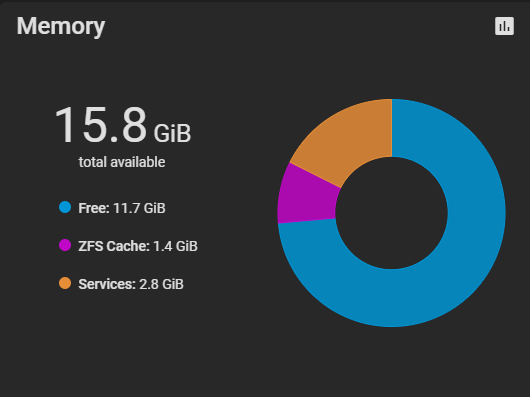
Se fai lavorare un pò il NAS vedi che la ARC si espande, quella schermata che hai messo sembra da appena acceso.
Spero di non dire una castroneria, ma da quello che avevo letto/capito questo è corretto per SCALE (cioè che assegna il 50% massimo della ram disponibile alla ARC), su CORE dovrebbe utilizzare tutta la ram disponibile meno una minima parte che si tiene dietro per sicurezza (e non so se sia una regola "empirica" o meno, ma ho letto sempre che per scegliere il quantitativo di ram, vada messo "almeno 1gb di ram ogni tb di archiviazione").
Lo scenario dello screen è probabilmente a macchina accesa da poco, ma ti assicuro che non cambia neanche dopo svariate ore di accensione (n.b. ovviamente se non faccio operazioni, altrimenti avoja se se la ciuccia tutta ahah).
Il dubbio che mi era venuto era come mai il sistema, nella schermata principale delle VM, indicasse come ram disponibile allo scopo 12gb, e poi invece allocasse tutto quello che ha indiscriminatamente... ma sembra risaputo che 16gb non siano sufficienti allo scopo.
Ho il tuo stesso problema (16Gb di ram), ma ho due slot liberi e sono DDR4 che è più facile da trovare.... Sono tentanto di buttarci su due banchi da 32GB, ma penso sia troppo (Ram vs CPU) e forse mi accontento di 2*16GB
Io putroppo ho solo 2 slot in totale, l'upgrade non è praticabile se non cambiando cpu+mobo, quindi per il momento accantono; non ti nascondo però che se dovesse capitarmi a tiro qualcosa di più recente adatto allo scopo ci farei un pensierino

Io al posto tuo comprerei un singolo modulo da 32gb (è vero che rinunceresti al dual channel ma *non credo* sia così impattante), rivenderei il kit attuale e con calma se necessario prenderei più in là un altro banchetto per arrivare a 64 (tra l'altro, solitamente a parità di capienza costa meno il singolo banco che il kit 2x).
Questo Buttare/Rendere, penso non vada bene neanche come ferma carte XD
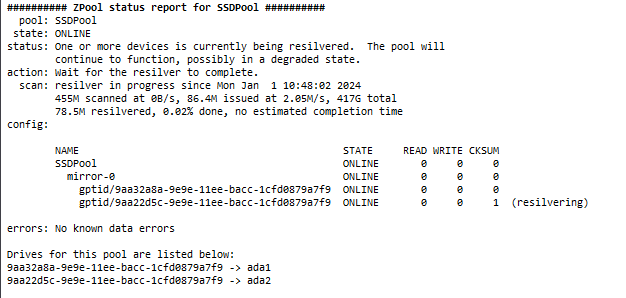
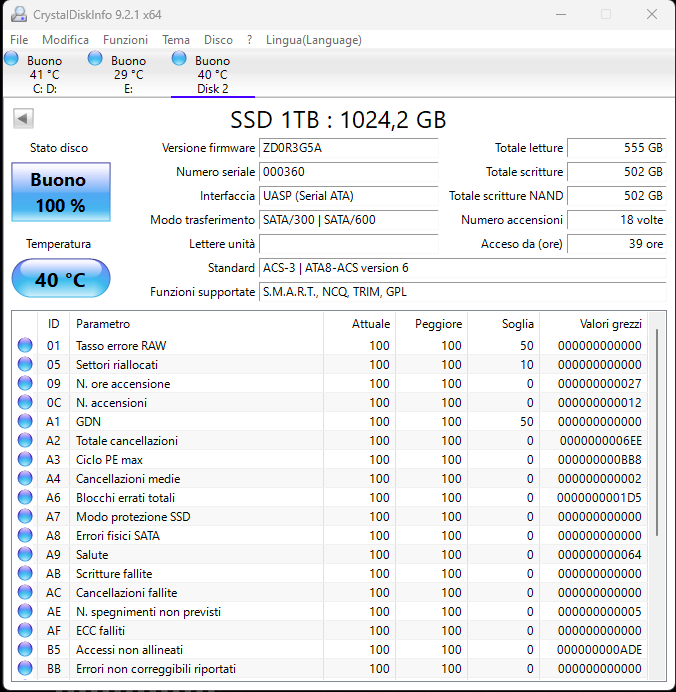
25TB scritti è praticamente nuovo :-(
Scherzi o sei serio? xD
a parte tutto, è già ripartito ieri, il negozio si "assicurerà del problema" ed effettuerà il rimborso.
Già dal "tono" del customer care sono sicuro che che avranno da ridire, faranno un test superficiale e diranno che è tutto ok, lo stesso test che avranno eseguito per metterlo in vendita così (sempre che ne abbiano veramente fatti!!), io ho comunque tutto salvato e male che vada apro contestazione con Paypal.
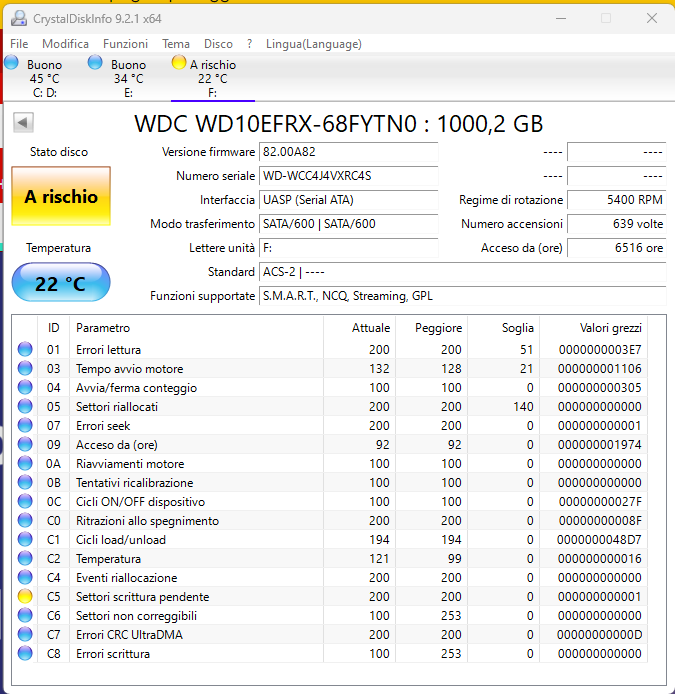
Per quanto riguarda l'altro sembra sano, pochi avvii e 3k ore (3 mesi di funzionamento).
Quanto hai per renderlo ? Lo metti in bench benchmark per 7gg e vedi se salta qualcosa fuori .
L'ho preso da un privato su subito.it (20€,+ 7€ spedizione e protezione acquirenti), quindi la protezione vale fino a che non confermo sia tutto in ordine... in ogni caso massimo 3 giorni; dopo aver constatato che i dati SMART erano gli stessi che mi aveva passato - fatto i test short e long ho confermato e quindi da adesso se mi abbandonasse è un mio problema.
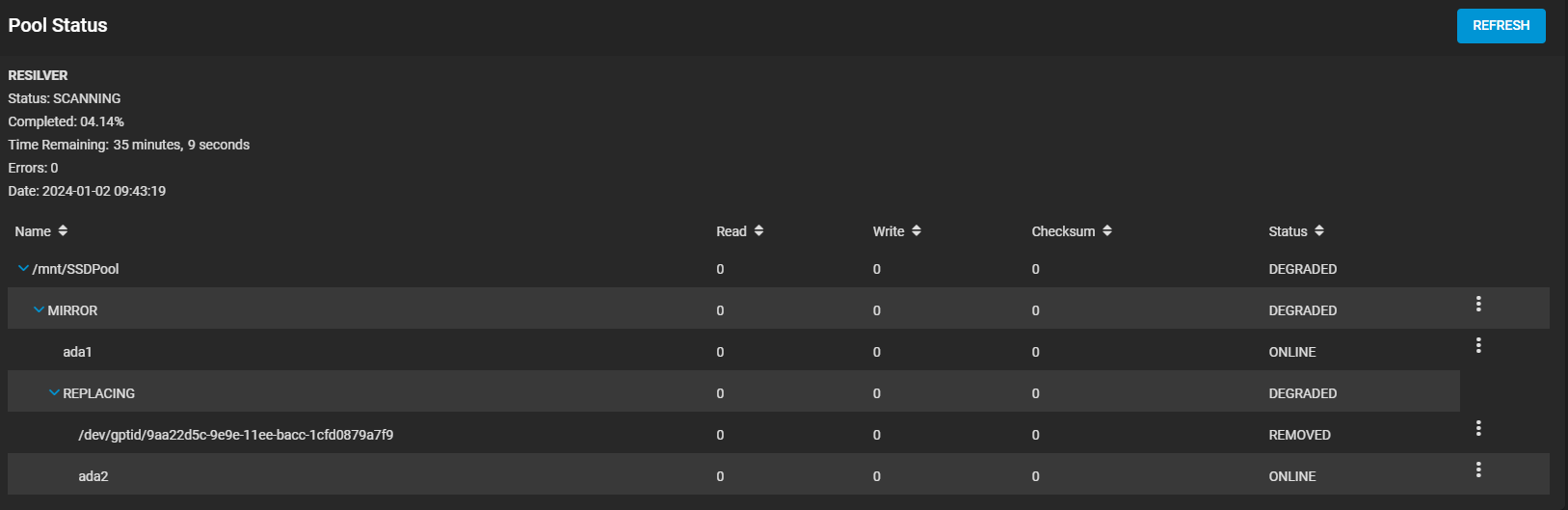
Al momento l'ho scollegato per non farlo accendere/spegnere a buffo, dato che ho dovuto comunque fare alcuni ravvii, e sto cercando un altro disco per metterlo in parità (ma sarà veramente difficile, questo è stato veramente un colpo di fortuna, penso mi dovrò buttare sul nuovo e a quel punto lo prendo direttamente da 2tb visto la differenza minima di prezzo).
EDIT: dimenticavo una cosa importante, mi spiegheresti nel dettaglio come metterlo sotto bench? così quando ho finito di "riassestare" la macchina la accendo e non la spengo più
Nel frattempo qualche giorno fa è arrivato anche lo switch, diavolo è veramente minuscolo non me l'aspettavo! Dalle foto sembrava più ingombrante, invece è così piccolo che entra in tasca!
A parte aver testato che funzioni tutto correttamente dopo aver spostato il NAS (è bastato collegare i cavi, nient'altro), non ho avuto modo di verificare se la situazione durante i trasferimenti in SMB sia migliorata... in ogni caso adesso devo sistemare i cavi di passaggio o mi tocca dormire in macchina (l'unico cavo abbastanza lungo che avevo per collegare router e switch è di un bel blu che risalta su tutto l'arredamento
).
Attendo anche che arrivi l'UPS, ho acquistato l'Epyc ION da 1000VA come dicevamo qualche settimana fa, mi è convenuto prenderlo direttamente da loro invece che da Amazon e l'ho portato a casa a 99€, quindi tra qualche giorno preparatevi che avrò sicuramente bisogno di qualche dritta per la configurazione xD