8. Tasks¶
The Tasks section of the web interface is used to configure repetitive tasks:
- Cron Jobs schedules a command or script to automatically execute at a specified time
- Init/Shutdown Scripts configures a command or script to automatically execute during system startup or shutdown
- Rsync Tasks schedules data synchronization to another system
- S.M.A.R.T. Tests schedules disk tests
- Periodic Snapshot Tasks schedules automatic creation of filesystem snapshots
- Replication Tasks automate the replication of snapshots to a remote system
- Resilver Priority controls the priority of resilvers
- Scrub Tasks schedules scrubs as part of ongoing disk maintenance
- Cloud Sync Tasks schedules data synchronization to cloud providers
Each of these tasks is described in more detail in this section.
Note
By default, Scrub Tasks are run once a month by an automatically-created task. S.M.A.R.T. Tests and Periodic Snapshot Tasks must be set up manually.
8.1. Cron Jobs¶
cron(8) is a daemon that runs a command or script on a regular schedule as a specified user.
Navigate to and click ADD to create a cron job. Figure 8.1.1 shows the configuration screen that appears.
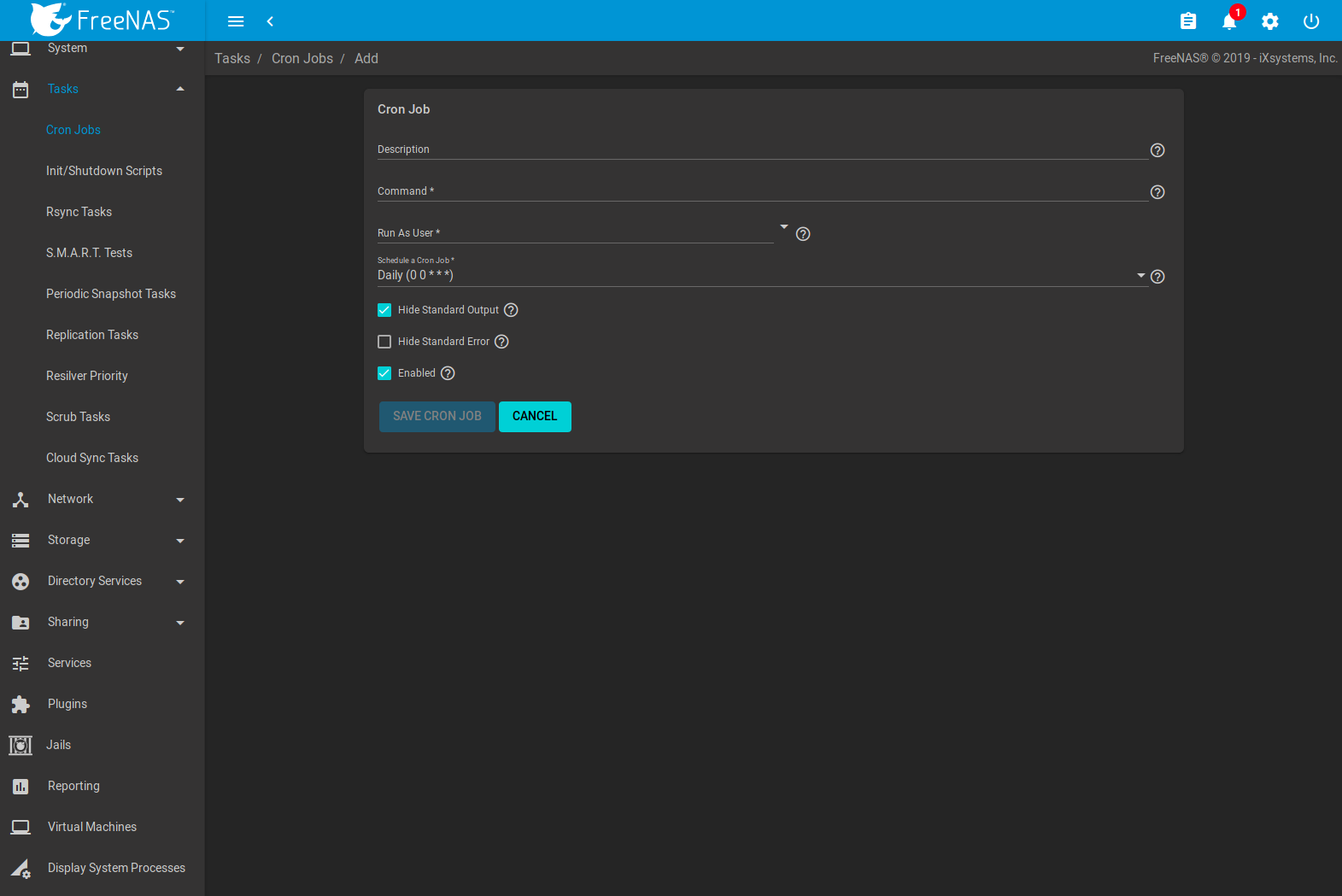
Fig. 8.1.1 Creating a Cron Job
Table 8.1.1 lists the configurable options for a cron job.
| Setting | Value | Description |
|---|---|---|
| Description | string | Enter a description of the cron job. |
| Command | drop-down menu | Enter the full path to the command or script to be run. If it is a script, testing it at the command line first is recommended. |
| Run As User | string | Select a user account to run the command. The user must have permissions allowing them to run the command or script. Output from executing a cron task is emailed to this user if Email has been configured for that user account. |
| Schedule a Cron Job | drop-down menu | Select how often to run the cron job. Choices are Hourly, Daily, Weekly, Monthly, or Custom. Selecting Custom opens the Advanced Scheduler. |
| Hide Standard Output | checkbox | Hide standard output (stdout) from the command. When unset, any standard output is mailed to the user account cron used to run the command. |
| Hide Standard Error | checkbox | Hide error output (stderr) from the command. When unset, any error output is mailed to the user account cron used to run the command. |
| Enable | checkbox | Enable this cron job. When unset, disable the cron job without deleting it. |
Cron jobs are shown in . This table displays the user, command, description, schedule, and whether the job is enabled. This table is adjustable by setting the different column checkboxes above it. Set Toggle to display all options in the table. Click (Options) for to show the Run Now, Edit, and Delete options.
Note
% symbols are automatically escaped and do not
need to be prefixed with backslashes. For example, use
date '+%Y-%m-%d' in a cron job to generate a filename based
on the date.
8.2. Init/Shutdown Scripts¶
FreeNAS® provides the ability to schedule commands or scripts to run at system startup or shutdown.
Go to and click ADD.
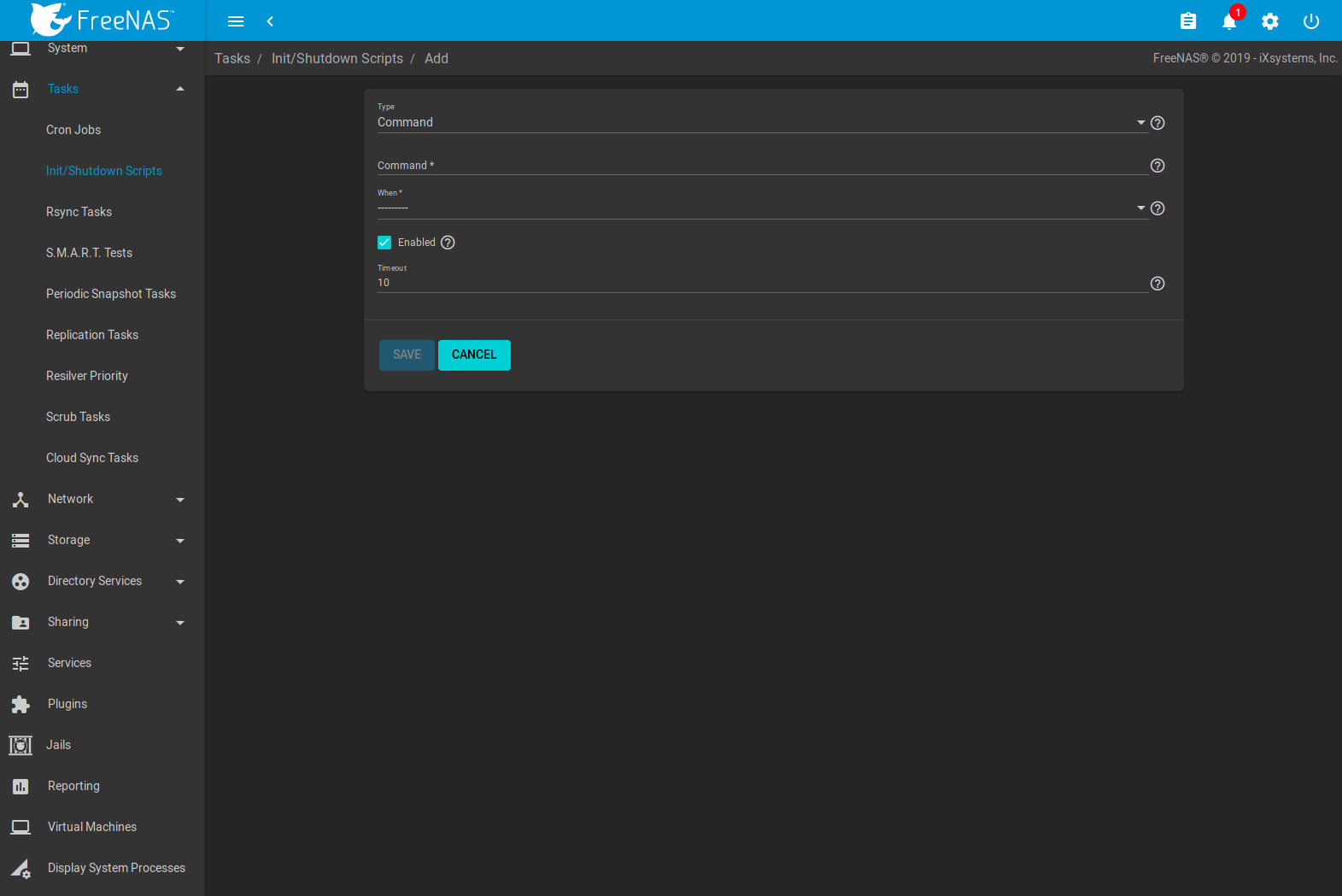
Fig. 8.2.1 Add an Init/Shutdown Command or Script
| Setting | Value | Description |
|---|---|---|
| Type | drop-down menu | Select Command for an executable or Script for an executable script. |
| Command or Script | string | If Command is selected, enter the command with any options. When Script is selected, click (Browse) to select the script from an existing pool. |
| When | drop-down menu | Select when the Command or Script runs:
|
| Enabled | checkbox | Enable this task. Unset to disable the task without deleting it. |
| Timeout | integer | Automatically stop the script or command after the specified number of seconds. |
Scheduled commands must be in the default path. The full path to the command can also be included in the entry. The path can be tested with which {commandname} in the Shell. When available, the path to the command is shown:
[root@freenas ~]# which ls
/bin/ls
When scheduling a script, test the script first to verify it is executable and achieves the desired results.
Note
Init/shutdown scripts are run with sh.
Init/Shutdown tasks are shown in . Click (Options) for a task to Edit or Delete that task.
8.3. Rsync Tasks¶
Rsync is a utility that copies specified data from one system to another over a network. Once the initial data is copied, rsync reduces the amount of data sent over the network by sending only the differences between the source and destination files. Rsync is used for backups, mirroring data on multiple systems, or for copying files between systems.
Rsync is most effective when only a relatively small amount of the data has changed. There are also some limitations when using rsync with Windows files. For large amounts of data, data that has many changes from the previous copy, or Windows files, Replication Tasks are often the faster and better solution.
Rsync is single-threaded and gains little from multiple processor cores.
To see whether rsync is currently running, use pgrep rsync from
the Shell.
Both ends of an rsync connection must be configured:
- the rsync server: this system pulls (receives) the data. This system is referred to as PULL in the configuration examples.
- the rsync client: this system pushes (sends) the data. This system is referred to as PUSH in the configuration examples.
FreeNAS® can be configured as either an rsync client or an rsync server. The opposite end of the connection can be another FreeNAS® system or any other system running rsync. In FreeNAS® terminology, an rsync task defines which data is synchronized between the two systems. To synchronize data between two FreeNAS® systems, create the rsync task on the rsync client.
FreeNAS® supports two modes of rsync operation:
- Module: exports a directory tree, and the configured settings of the tree as a symbolic name over an unencrypted connection. This mode requires that at least one module be defined on the rsync server. It can be defined in the FreeNAS® web interface under . In other operating systems, the module is defined in rsyncd.conf(5).
- SSH: synchronizes over an encrypted connection. Requires the configuration of SSH user and host public keys.
This section summarizes the options when creating an rsync task. It then provides a configuration example between two FreeNAS® systems for each mode of rsync operation.
Note
If there is a firewall between the two systems or if the other system has a built-in firewall, make sure that TCP port 873 is allowed.
Figure 8.3.1 shows the screen that appears after navigating to and clicking ADD. Table 8.3.1 summarizes the configuration options available when creating an rsync task.
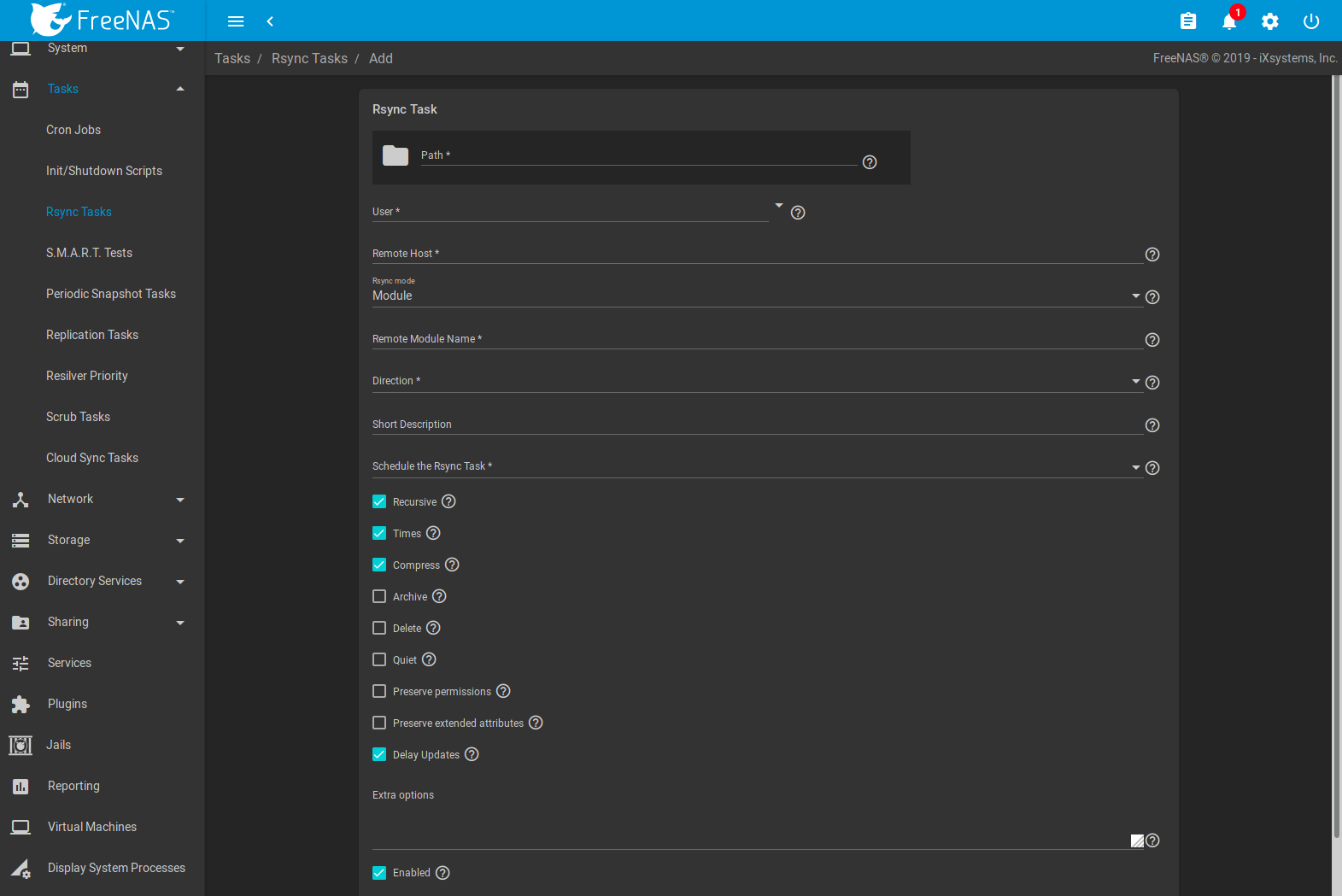
Fig. 8.3.1 Adding an Rsync Task
| Setting | Value | Description |
|---|---|---|
| Path | browse button | Browse to the path to be copied. FreeNAS® verifies that the remote path exists. FreeBSD path length limits apply on the FreeNAS® system. Other operating systems can have different limits which might affect how they can be used as sources or destinations. |
| User | drop-down menu | Select the user to run the rsync task. The user selected must have permissions to write to the specified directory on the remote host. |
| Remote Host | string | Enter the IP address or hostname of the remote system that will store the copy. Use the format username@remote_host if the username differs on the remote host. |
| Remote SSH Port | integer | Only available in SSH mode. Allows specifying an SSH port other than the default of 22. |
| Rsync mode | drop-down menu | The choices are Module mode or SSH mode. |
| Remote Module Name | string | At least one module must be defined in rsyncd.conf(5) of the rsync server or in the Rsync Modules of another system. |
| Remote Path | string | Only appears when using SSH mode. Enter the existing path on the remote host to sync with, for example, /mnt/pool. Note that the path length cannot be greater than 255 characters. |
| Validate Remote Path | checkbox | Verifies the existence of the Remote Path. |
| Direction | drop-down menu | Direct the flow of the data to the remote host. Choices are Push or Pull. Default is to push to a remote host. |
| Short Description | string | Enter a description of the rsync task. |
| Schedule the Rsync Task | drop-down menu | Choose how often to run the task. Choices are Hourly, Daily, Weekly, Monthly, or Custom. Selecting Custom opens the Advanced Scheduler. |
| Recursive | checkbox | Set to include all subdirectories of the specified directory. When unset, only the specified directory is included. |
| Times | checkbox | Set to preserve the modification times of files. |
| Compress | checkbox | Set to reduce the size of the data to transmit. Recommended for slow connections. |
| Archive | checkbox | When set, rsync is run recursively, preserving symlinks, permissions, modification times,
group, and special files. When run as root, owner, device files, and special files are
also preserved. Equivalent to rsync -rlptgoD. |
| Delete | checkbox | Set to delete files in the destination directory that do not exist in the source directory. |
| Quiet | checkbox | Suppress rsync task status alerts. |
| Preserve permissions | checkbox | Set to preserve original file permissions. This is useful when the user is set to root. |
| Preserve extended attributes | checkbox | Extended attributes are preserved, but must be supported by both systems. |
| Delay Updates | checkbox | Set to save the temporary file from each updated file to a holding directory until the end of the transfer when all transferred files are renamed into place. |
| Extra options | string | Additional rsync(1) options to include.
Note: The * character
must be escaped with a backslash (\*.txt)
or used inside single quotes. ('*.txt') |
| Enabled | checkbox | Enable this rsync task. Unset to disable this rsync task without deleting it. |
If the rysnc server requires password authentication, enter
--password-file=/PATHTO/FILENAME in the
Extra options field, replacing /PATHTO/FILENAME
with the appropriate path to the file containing the password.
Created rsync tasks are listed in Rsync Tasks. Click (Options) for an entry to display buttons for Edit, Delete, or Run Now.
The Status column shows the status of the rsync task. To view the detailed rsync logs for a task, click the Status entry when the task is running or finished.
Rsync tasks also generate an Alert on task completion. The alert shows if the task succeeded or failed.
8.3.1. Rsync Module Mode¶
This configuration example configures rsync module mode between the two following FreeNAS® systems:
- 192.168.2.2 has existing data in
/mnt/local/images. It will be the rsync client, meaning that an rsync task needs to be defined. It will be referred to as PUSH. - 192.168.2.6 has an existing pool named
/mnt/remote. It will be the rsync server, meaning that it will receive the contents of/mnt/local/images. An rsync module needs to be defined on this system and the rsyncd service needs to be started. It will be referred to as PULL.
On PUSH, an rsync task is defined in , ADD. In this example:
- the Path points to
/usr/local/images, the directory to be copied - the Remote Host points to 192.168.2.6, the IP address of the rsync server
- the Rsync Mode is Module
- the Remote Module Name is backups; this will need to be defined on the rsync server
- the Direction is Push
- the rsync is scheduled to occur every 15 minutes
- the User is set to root so it has permission to write anywhere
- the Preserve Permissions option is enabled so that the original permissions are not overwritten by the root user
On PULL, an rsync module is defined in , ADD. In this example:
- the Module Name is backups; this needs to match the setting on the rsync client
- the Path is
/mnt/remote; a directory calledimageswill be created to hold the contents of/usr/local/images - the User is set to root so it has permission to write anywhere
Descriptions of the configurable options can be found in Rsync Modules.
- Hosts allow is set to 192.168.2.2, the IP address of the rsync client
To finish the configuration, start the rsync service on PULL in
.
If the rsync is successful, the contents of
/mnt/local/images/ will be mirrored to
/mnt/remote/images/.
8.3.2. Rsync over SSH Mode¶
SSH replication mode does not require the creation of an rsync module or for the rsync service to be running on the rsync server. It does require SSH to be configured before creating the rsync task:
- a public/private key pair for the rsync user account (typically root) must be generated on PUSH and the public key copied to the same user account on PULL
- to mitigate the risk of man-in-the-middle attacks, the public host key of PULL must be copied to PUSH
- the SSH service must be running on PULL
To create the public/private key pair for the rsync user account, open Shell on PUSH and run ssh-keygen. This example generates an RSA type public/private key pair for the root user. When creating the key pair, do not enter the passphrase as the key is meant to be used for an automated task.
ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
f5:b0:06:d1:33:e4:95:cf:04:aa:bb:6e:a4:b7:2b:df root@freenas.local
The key's randomart image is:
+--[ RSA 2048]----+
| .o. oo |
| o+o. . |
| . =o + |
| + + o |
| S o . |
| .o |
| o. |
| o oo |
| **oE |
|-----------------|
| |
|-----------------|
FreeNAS® supports RSA keys for SSH. When creating the key, use
-t rsa to specify this type of key. Refer to
Key-based Authentication
for more information.
Note
If a different user account is used for the rsync task, use the su - command after mounting the filesystem but before generating the key. For example, if the rsync task is configured to use the user1 user account, use this command to become that user:
su - user1
Next, view and copy the contents of the generated public key:
more .ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1lBEXRgw1W8y8k+lXPlVR3xsmVSjtsoyIzV/PlQPo
SrWotUQzqILq0SmUpViAAv4Ik3T8NtxXyohKmFNbBczU6tEsVGHo/2BLjvKiSHRPHc/1DX9hofcFti4h
dcD7Y5mvU3MAEeDClt02/xoi5xS/RLxgP0R5dNrakw958Yn001sJS9VMf528fknUmasti00qmDDcp/kO
xT+S6DFNDBy6IYQN4heqmhTPRXqPhXqcD1G+rWr/nZK4H8Ckzy+l9RaEXMRuTyQgqJB/rsRcmJX5fApd
DmNfwrRSxLjDvUzfywnjFHlKk/+TQIT1gg1QQaj21PJD9pnDVF0AiJrWyWnR root@freenas.local
Go to PULL and paste (or append) the copied key into the SSH Public Key field of (Options) , or the username of the specified rsync user account. The paste for the above example is shown in Figure 8.3.2. When pasting the key, ensure that it is pasted as one long line and, if necessary, remove any extra spaces representing line breaks.
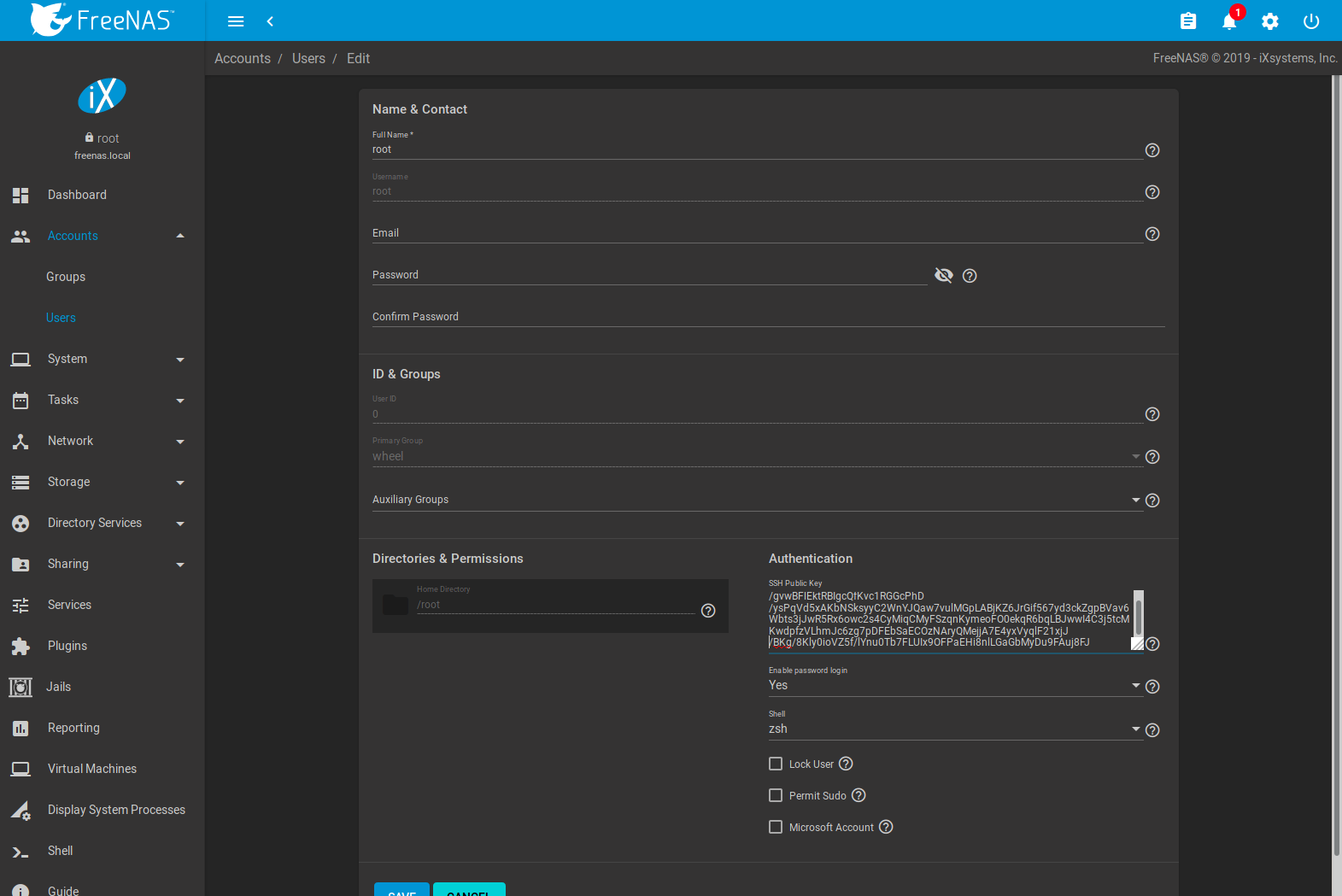
Fig. 8.3.2 Pasting the User SSH Public Key
While on PULL, verify that the SSH service is running in and start it if it is not.
Next, copy the host key of PULL using Shell on PUSH. The
command copies the RSA host key of the PULL server used in our
previous example. Be sure to include the double bracket >> to
prevent overwriting any existing entries in the known_hosts
file:
ssh-keyscan -t rsa 192.168.2.6 >> /root/.ssh/known_hosts
Note
If PUSH is a Linux system, use this command to copy the RSA key to the Linux system:
cat ~/.ssh/id_rsa.pub | ssh user@192.168.2.6 'cat >> .ssh/authorized_keys'
The rsync task can now be created on PUSH. To configure rsync SSH mode using the systems in our previous example, the configuration is:
- the Path points to
/mnt/local/images, the directory to be copied - the Remote Host points to 192.168.2.6, the IP address of the rsync server
- the Rsync Mode is SSH
- the rsync is scheduled to occur every 15 minutes
- the User is set to root so it has permission to write anywhere; the public key for this user must be generated on PUSH and copied to PULL
- the Preserve Permissions option is enabled so that the original permissions are not overwritten by the root user
Save the rsync task and the rsync will automatically occur according
to the schedule. In this example, the contents of
/mnt/local/images/ will automatically appear in
/mnt/remote/images/ after 15 minutes. If the content does not
appear, use Shell on PULL to read /var/log/messages. If the
message indicates a n (newline character) in the key, remove the
space in the pasted key–it will be after the character that appears
just before the n in the error message.
8.4. S.M.A.R.T. Tests¶
S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) is a monitoring system for computer hard disk drives to detect and report on various indicators of reliability. Replace the drive when a failure is anticipated by S.M.A.R.T. Most modern ATA, IDE, and SCSI-3 hard drives support S.M.A.R.T. – refer to the drive documentation for confirmation.
Click and ADD to add a new scheduled S.M.A.R.T. test. Figure 8.4.1 shows the configuration screen that appears. Tests are listed under S.M.A.R.T. Tests. After creating tests, check the configuration in , then click the power button for the S.M.A.R.T. service in to activate the service. The S.M.A.R.T. service will not start if there are no pools.
Note
To prevent problems, do not enable the S.M.A.R.T. service if the disks are controlled by a RAID controller. It is the job of the controller to monitor S.M.A.R.T. and mark drives as Predictive Failure when they trip.
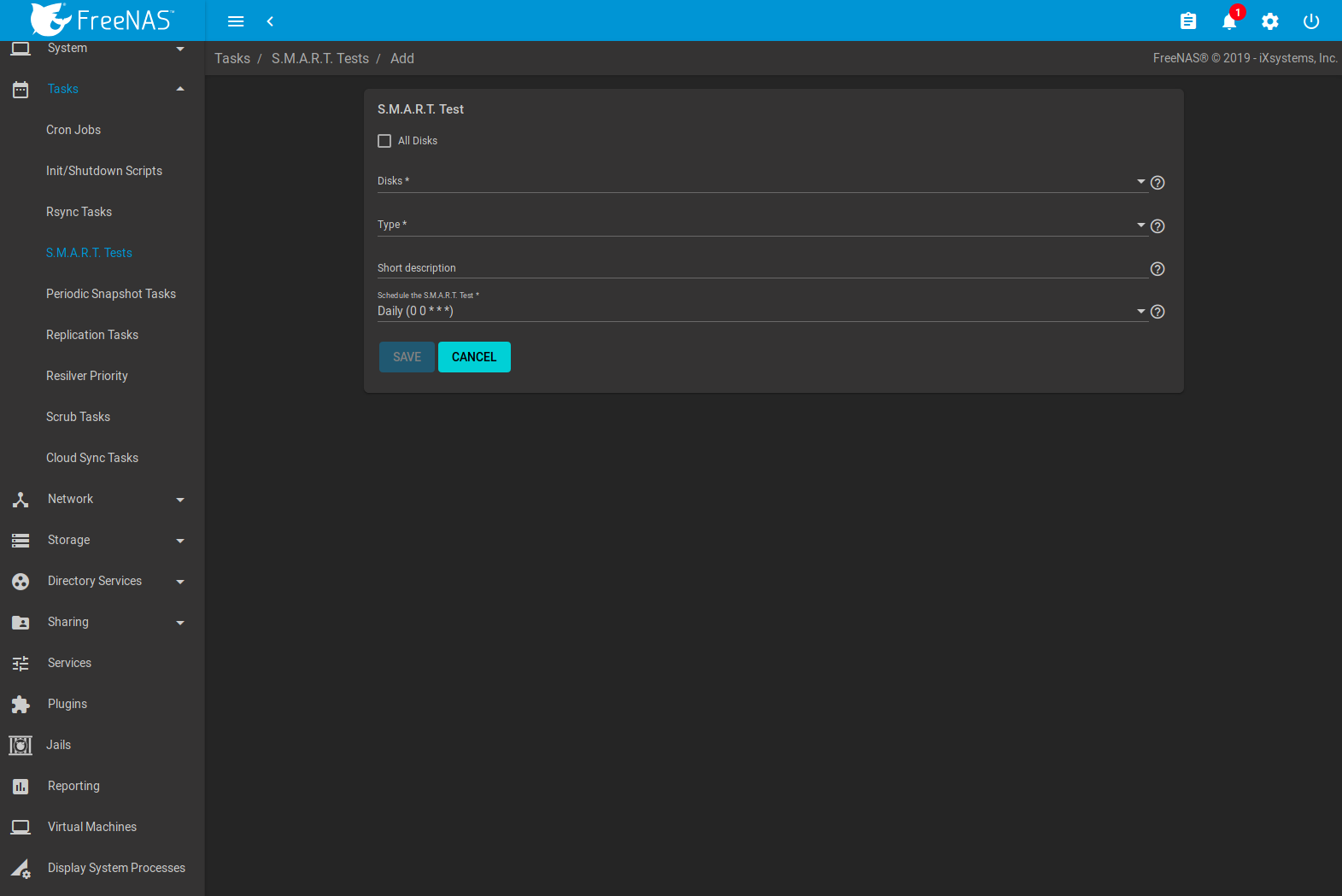
Fig. 8.4.1 Adding a S.M.A.R.T. Test
Table 8.4.1 summarizes the configurable options when creating a S.M.A.R.T. test.
| Setting | Value | Description |
|---|---|---|
| All Disks | checkbox | Set to monitor all disks. |
| Disks | drop-down menu | Select the disks to monitor. Available when All Disks is unset. |
| Type | drop-down menu | Choose the test type. See smartctl(8) for descriptions of each type. Some test types will degrade performance or take disks offline. Avoid scheduling S.M.A.R.T. tests simultaneously with scrub or resilver operations. |
| Short description | string | Optional. Enter a description of the S.M.A.R.T. test. |
| Schedule the S.M.A.R.T. Test | drop-down menu | Choose how often to run the task. Choices are Hourly, Daily, Weekly, Monthly, or Custom. Selecting Custom opens the Advanced Scheduler. |
An example configuration is to schedule a Short Self-Test once a week and a Long Self-Test once a month. These tests do not have a performance impact, as the disks prioritize normal I/O over the tests. If a disk fails a test, even if the overall status is Passed, consider replacing that disk.
Warning
Some S.M.A.R.T. tests cause heavy disk activity and can drastically reduce disk performance. Do not schedule S.M.A.R.T. tests to run at the same time as scrub or resilver operations or during other periods of intense disk activity.
Which tests will run and when can be verified by typing smartd -q showtests within Shell.
The results of a test can be checked from Shell by specifying the name of the drive. For example, to see the results for disk ada0, type:
smartctl -l selftest /dev/ada0
8.5. Periodic Snapshot Tasks¶
A periodic snapshot task allows scheduling the creation of read-only versions of pools and datasets at a given point in time. Snapshots can be created quickly and, if little data changes, new snapshots take up very little space. For example, a snapshot where no files have changed takes 0 MB of storage, but as changes are made to files, the snapshot size changes to reflect the size of the changes.
Snapshots keep a history of files, providing a way to recover an older copy or even a deleted file. For this reason, many administrators take snapshots often, store them for a period of time, and store them on another system, typically using Replication Tasks. Such a strategy allows the administrator to roll the system back to a specific point in time. If there is a catastrophic loss, an off-site snapshot can be used to restore the system up to the time of the last snapshot.
A pool must exist before a snapshot can be created. Creating a pool is described in Pools.
To create a periodic snapshot task, navigate to and click ADD. This opens the screen shown in Figure 8.5.1. Table 8.5.1 describes the fields in this screen.
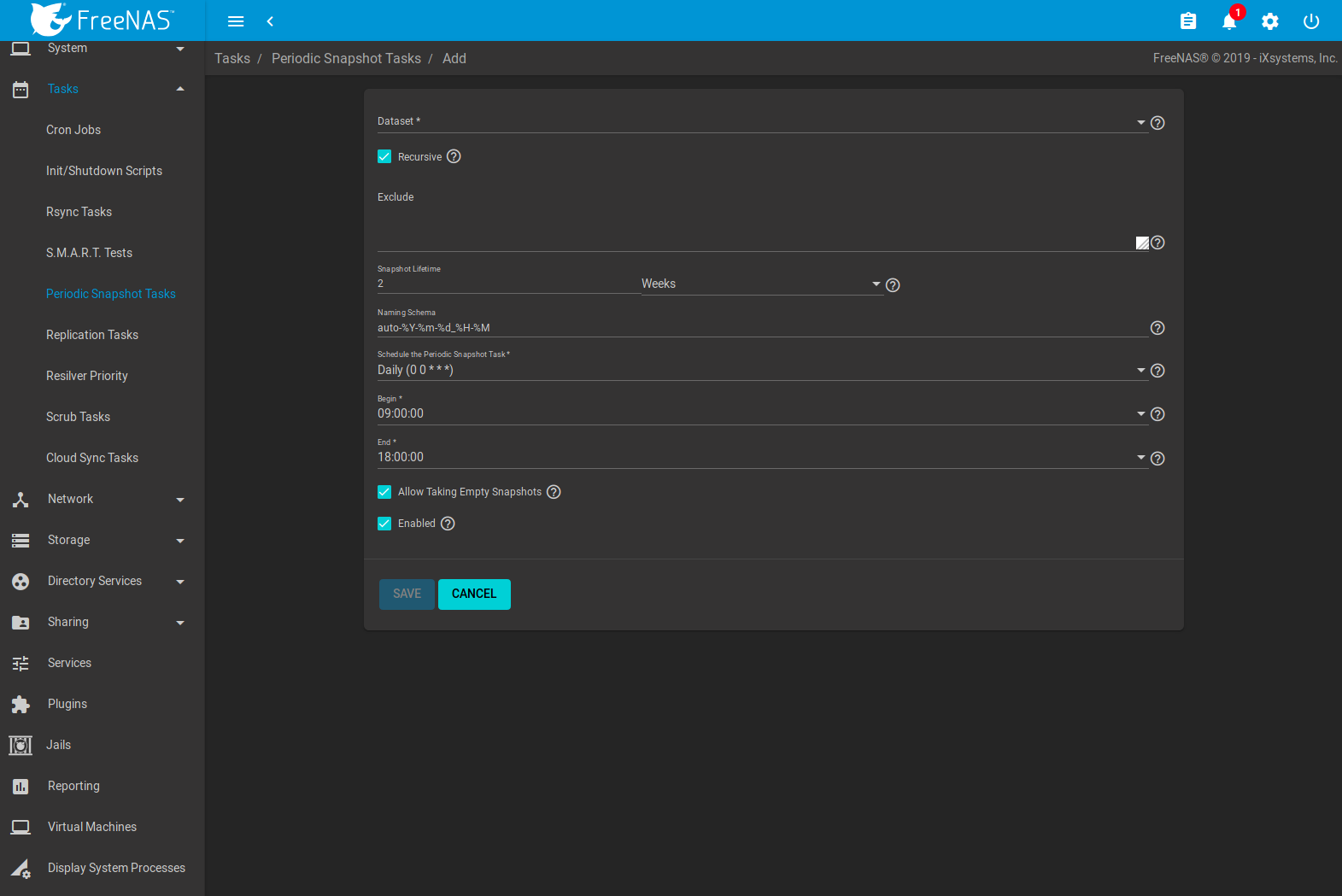
Fig. 8.5.1 Creating a Periodic Snapshot
| Setting | Value | Description |
|---|---|---|
| Dataset | drop-down menu | Select an existing dataset, or zvol. |
| Recursive | checkbox | Set this option to take separate snapshots of the pool or dataset and each of the child datasets. Deselect to take a single snapshot of the specified pool or dataset with no child datasets. |
| Exclude | string | Exclude specific child dataset snapshots from the snapshot. Use with Recursive snapshots. Add
one child dataset name per line. Example: pool1/dataset1/child1. A recursive snapshot of
pool1/dataset1 includes all child dataset snapshots except child1. |
| Snapshot Lifetime | integer and drop-down menu | Define a length of time to retain the snapshot on this system. After the time expires, the snapshot is removed. Snapshots replicated to other systems are not affected. |
| Snapshot Lifetime Unit | drop-down | Select a unit of time to retain the snapshot on this system. |
| Naming Schema | string | Snapshot name format string. The default is auto-%Y-%m-%d_%H-%M. Must include the strings %Y, %m
%d, %H, and %M. These strings are replaced with the four-digit year, month, day of month, hour, and
minute as defined in strftime(3). Example:
backups_%Y-%m-%d_%H:%M |
| Schedule the Periodic Snapshot Task | drop-down menu | When the periodic snapshot will run. Choose one of the preset schedules or choose Custom to use the Advanced Scheduler. |
| Begin | drop-down menu | Hour and minute when the system can begin taking snapshots. |
| End | drop-down menu | Hour and minute the system must stop creating snapshots. Snapshots already in progress will continue until complete. |
| Allow Taking Empty Snapshots | checkbox | Creates dataset snapshots when there are no changes. Set to support periodic snapshot schedules and replications created in FreeNAS® 11.2 and earlier. |
| Enabled | checkbox | Set to activate this periodic snapshot schedule. |
Setting Recursive adds child datasets to the snapshot. Creating separate snapshots for each child dataset is not needed.
Click SAVE when finished customizing the task. Defined tasks are listed alphabetically in .
Click (Options) for a periodic snapshot task to see options to Edit or Delete the scheduled task.
Deleting a dataset does not delete snapshot tasks for that dataset. To re-use the snapshot task for a different dataset, Edit the task and choose the new Dataset. The original dataset is shown in the drop-down, but cannot be selected.
8.6. Replication¶
Replication is the process of copying ZFS dataset snapshots from one storage pool to another. Replications can be configured to copy snapshots to another pool on the local system or send copies to a remote system that is in a different physical location.
Replication schedules are typically paired with Periodic Snapshot Tasks to generate local copies of important data and replicate these copies to a remote system.
Replications require a source system with dataset snapshots and a destination that can store the copied data. Remote replications require a saved SSH Connection on the source system and the destination system must be configured to allow SSH connections. Local replications do not use SSH.
First-time replication tasks can take a long time to complete as the entire dataset snapshot must be copied to the destination system. Replicated data is not visible on the receiving system until the replication task is complete.
Later replications only send incremental snapshot changes to the destination system. This reduces both the total space required by replicated data and the network bandwidth required for the replication to complete.
The target dataset on the destination system is created in read-only mode to protect the data. To mount or browse the data on the destination system, use a clone of the snapshot. Clones are created in read/write mode, making it possible to browse or mount them. See Snapshots for more details.
Replications run in parallel as long as they do not conflict with each other. Completion time depends on the number and size of snapshots and the bandwidth available between the source and destination computers.
Examples in this section refer to the FreeNAS® system with the original datasets for snapshot and replication as Primary and the FreeNAS® system that is storing replicated snapshots as Secondary.
8.6.1. Replication Creation Wizard¶
To create a new replication, go to and click ADD.
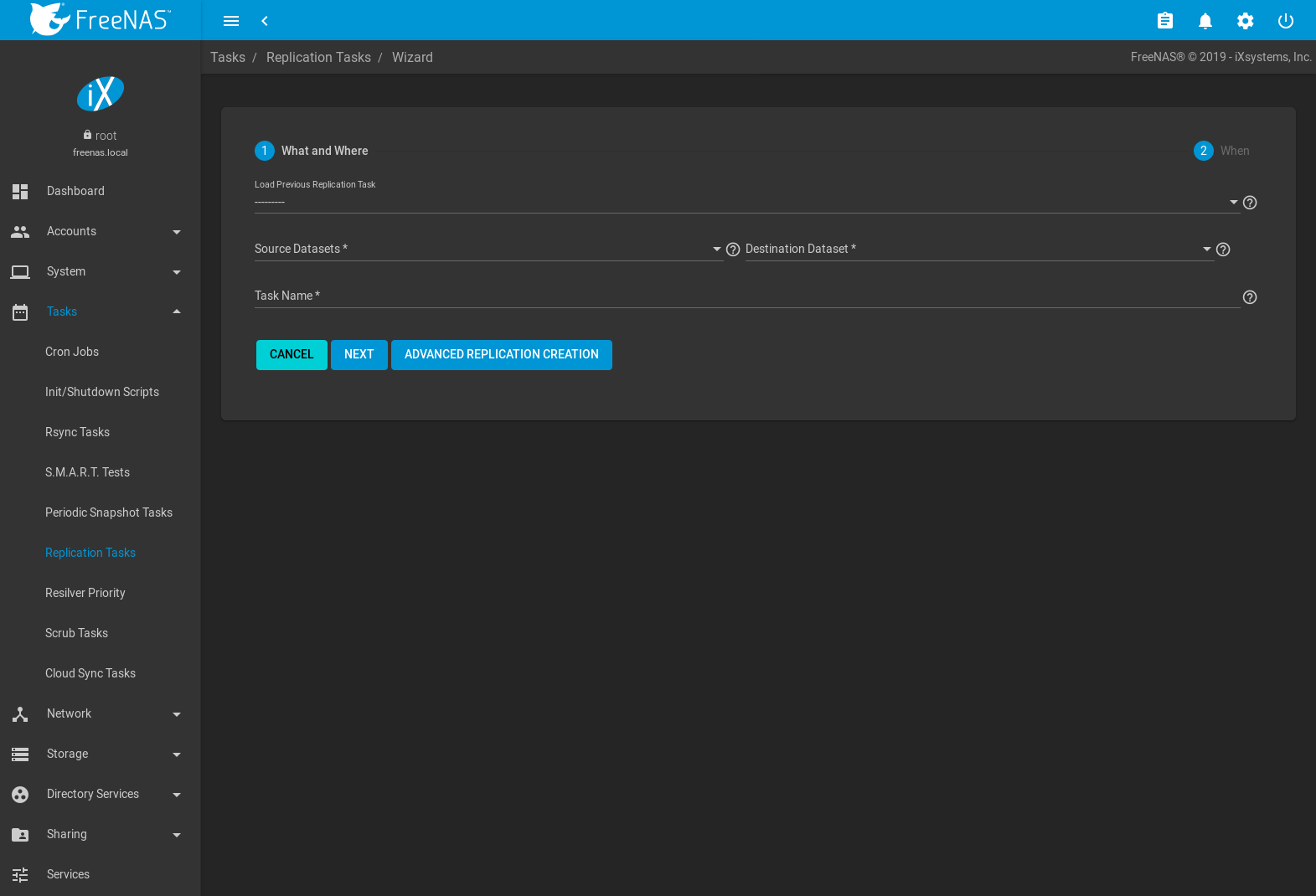
Fig. 8.6.1 Replication Wizard: What and Where
The wizard allows loading previously saved replication configurations and simplifies many replication settings. To see all possible replication creation options, click ADVANCED REPLICATION CREATION.
Using the wizard to create a new replication task begins by defining what is being replicated and where. Choosing On a Different System for either the Sources Datasets or Destination Dataset requires an SSH Connection to the remote system. Open the drop-down menu to choose an SSH connection or click Create New to add a new connection.
To choose a dataset, click (Browse) and select the dataset from the expandable tree. Multiple Source Datasets can be chosen.
Start by selecting the Source Datasets to be replicated. Source datasets on a remote system need a Periodic Snapshot Task, or the snapshots can be manually selected by setting Replicate Custom Snapshots and entering a snapshot Naming Schema. The schema is a pattern of the name and strftime(3) %Y, %m, %d, %H, and %M strings that match names of the snapshots to include in the replication. The number of matching snapshots is shown. There is also a Recursive option to include child datasets with the selected datasets.
Now choose the Destination Dataset to receive the replicated snapshots. Only a single dataset can be chosen.
Using an SSH connection for replication adds the SSH Transfer Security option. This sets the data transfer security level. The connection is authenticated with SSH. Data can be encrypted during transfer for security or left unencrypted to maximize transfer speed. WARNING: Encryption is recommended, but can be disabled for increased speed on secure networks.
A suggested replication Task Name is shown. This can be changed to give a more meaningful name to the task. When the source and destination have been set, click NEXT to choose when the replication will run.
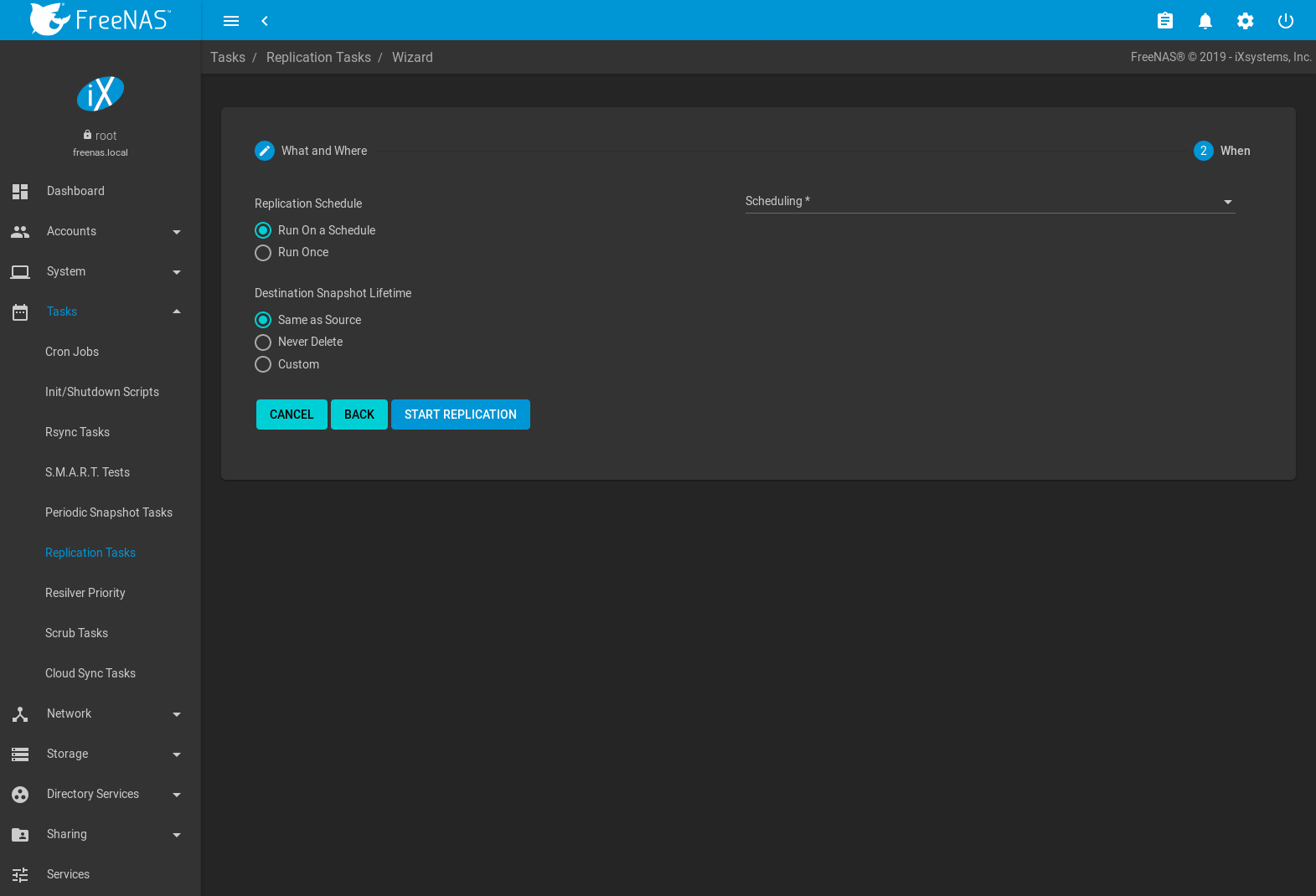
Fig. 8.6.2 Replication Wizard: When
The replication task can be configured to run on a schedule or left unscheduled and manually activated. Choosing Run On a Schedule adds the Scheduling drop-down to choose from preset schedules or define a Custom replication schedule.
Destination Snapshot Lifetime determines when replicated snapshots are deleted from the destination system:
- Same as Source: duplicate the configured Snapshot Lifetime value from the source dataset periodic snapshot task.
- Never Delete: never delete snapshots from the destination system.
- Custom: define how long a snapshot remains on the destination system. Enter a number and choose a measure of time from the drop-down menus.
Clicking START REPLICATION saves the replication configuration and activates the schedule. When the replication configuration includes a source dataset on the local system and has a schedule, a periodic snapshot task of that dataset is also created.
8.6.2. Advanced Replication Creation¶
The advanced replication creation screen has more options for fine-tuning a replication. It also allows creating local replications, legacy engine replications from FreeNAS® 11.1 or earlier, or even creating a one-time replication that is not linked to a periodic snapshot task.
Go to , click ADD and ADVANCED REPLICATION CREATION to see these options. This screen is also displayed after clicking (Options) and Edit for an existing replication.
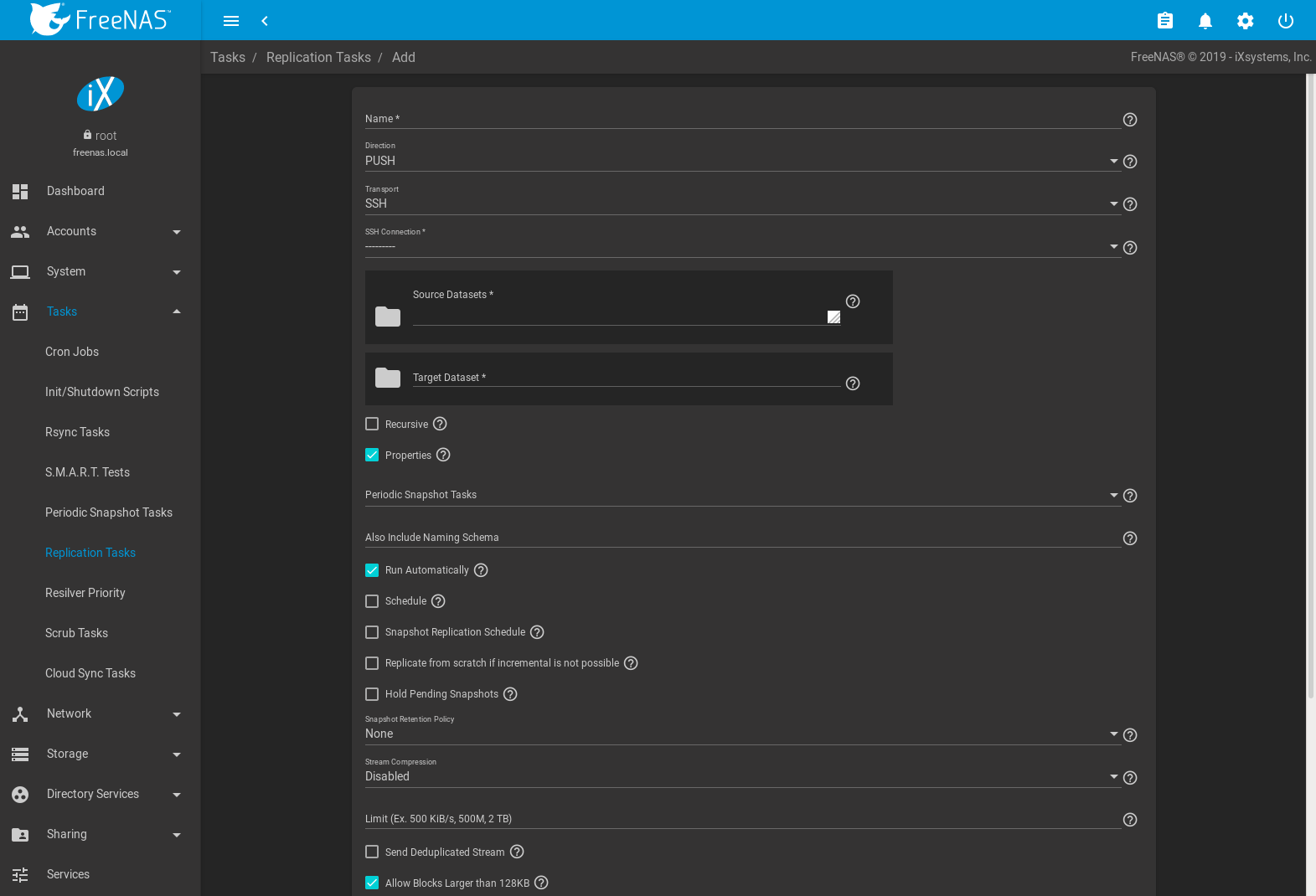
The Transport value changes many of the options for
replication. Table 8.6.1
shows abbreviated names of the Transport methods in the
Transport column to identify fields which appear when that
method is selected.
ALL: All Transport methodsSSH: SSHNCT: SSH+NETCATLOC: LOCALLEG: LEGACY
| Setting | Transport | Value | Description |
|---|---|---|---|
| Name | All | string | Descriptive name for the replication. |
| Direction | SSH, NCT, LEG | drop-down menu | PUSH sends snapshots to a destination system. PULL connects to a remote system and retrieves snapshots matching a Naming Schema. |
| Transport | All | drop-down menu | Method of snapshot transfer:
|
| SSH Connection | SSH, NCT, LEG | drop-down menu | Choose the SSH connection. |
| Netcat Active Side | NCT | drop-down menu | Establishing a connection requires that one of the connection systems has open TCP ports. Choose which system (LOCAL or REMOTE) will open ports. Consult your IT department to determine which systems are allowed to open ports. |
| Netcat Active Side Listen Address | NCT | string | IP address on which the connection Active Side listens. Defaults to 0.0.0.0. |
| Netcat Active Side Min Port | NCT | integer | Lowest port number of the active side listen address that is open to connections. |
| Netcat Active Side Max Port | NCT | integer | Highest port number of the active side listen address that is open to connections. The first available port between the minimum and maximum is used. |
| Netcat Active Side Connect Address | NCT | string | Hostname or IP address used to connect to the active side system. When the active side is LOCAL, this
defaults to the SSH_CLIENT environment variable. When the active side is REMOTE, this defaults
to the SSH connection hostname. |
| Source Datasets | All | (Browse) | Choose datasets on the source system to be replicated. Click (Browse) to see all datasets on the source system. Each dataset must have an associated periodic snapshot task, or previously-created snapshots for a one-time replication. |
| Target Dataset | All | (Browse) | Choose a dataset on the destination system where snapshots are stored. Click (Browse) to see all datasets on the destination system. Click a dataset to set it as the target. |
| Recursive | All | checkbox | Replicate all child dataset snapshots. When set, Exclude Child Datasets becomes visible. |
| Exclude Child Datasets | SSH, NCT, LOC | string | Exclude specific child dataset snapshots from the replication. Use with Recursive snapshots. List
child dataset names to exclude. Example: pool1/dataset1/child1. A recursive replication of
pool1/dataset1 snapshots includes all child dataset snapshots except child1. |
| Properties | All | checkbox | Include dataset properties with the replicated snapshots. |
| Periodic Snapshot Tasks | SSH, NCT, LOC | drop-down menu | Snapshot schedule for this replication task. Choose from configured Periodic Snapshot Tasks. This replication task must have the same Recursive and Exclude Child Datasets values as the chosen periodic snapshot task. Selecting a periodic snapshot schedule removes the Schedule field. |
| Naming Schema | SSH, NCT, LOC | string | Visible with PULL replications. Pattern of naming custom snapshots to be replicated. Enter the name and strftime(3) %Y, %m, %d, %H, and %M strings that match the snapshots to include in the replication. |
| Also Include Naming Schema | SSH, NCT, LOC | string | Visible with PUSH replications. Pattern of naming custom snapshots to include in the replication with the periodic snapshot schedule. Enter the strftime(3) strings that match the snapshots to include in the replication. When a periodic snapshot is not linked to the replication, enter the naming schema for manually created snapshots. Has the same %Y, %m, %d, %H, and %M string requirements as the Naming Schema in a periodic snapshot task. |
| Run Automatically | SSH, NCT, LOC | checkbox | Set to either start this replication task immediately after the linked periodic snapshot task completes or continue to create a separate Schedule for this replication. |
| Schedule | SSH, NCT, LOC | checkbox and drop-down menu | Start time for the replication task. Select a preset schedule or choose Custom to use the advanced scheduler. Adds the Begin and End fields. |
| Begin | SSH, NCT, LOC | drop-down menu | Start time for the replication task. |
| End | SSH, NCT, LOC | drop-down menu | End time for the replication task. A replication that is already in progress can continue to run past this time. |
| Snapshot Replication Schedule | SSH, NCT, LOC | checkbox and drop-down menu | Schedule which periodic snapshots will be replicated. All snapshots will be replicated by default. To choose which snapshots are replicated, set the checkbox and select a schedule from the drop-down menu. For example, there is a a system that takes a snapshot every hour, but the administrator has decided that only every other snapshot is needed for replication. The scheduler is set to even hours and only snapshots taken at those times are replicated. |
| Begin | SSH, NCT, LOC | drop-down menu | Set a starting time when the replication is not allowed to start. A replication that is already in progress can continue to run past this time. |
| End | SSH, NCT, LOC | drop-down menu | Set an ending time for when replications are not allowed to start. |
| Only Replicate Snapshots Matching Schedule | SSH, NCT, LOC | checkbox | Set to either use the Schedule in place of the Snapshot Replication Schedule or add the Schedule values to the Snapshot Replication Schedule. |
| Replicate from scratch if incremental is not possible | SSH, NCT, LOC | checkbox | If the destination system has snapshots but they do not have any data in common with the source snapshots, destroy all destination snapshots and do a full replication. Warning: enabling this option can cause data loss or excessive data transfer if the replication is misconfigured. |
| Hold Pending Snapshots | SSH, NCT, LOC | checkbox | Prevent source system snapshots that have failed replication from being automatically removed by the Snapshot Retention Policy. |
| Snapshot Retention Policy | SSH, NCT, LOC | drop-down menu | When replicated snapshots are deleted from the destination system:
|
| Snapshot Lifetime | All | integer and drop-down menu | Added with a Custom retention policy. How long a snapshot remains on the destination system. Enter a number and choose a measure of time from the drop-down. |
| Stream Compression | SSH | drop-down menu | Select a compression algorithm to reduce the size of the data being replicated. Only appears when SSH is chosen for Transport. |
| Limit (Ex. 500 KiB, 500M, 2 TB) | SSH | integer | Limit replication speed to this number of bytes per second. Zero means no limit. Units like k,
KiB, and M can be used. Numbers without unit letters are interpreted as bytes.
For example, 500M sets the replication speed to 500 megabytes per second. |
| Send Deduplicated Stream | SSH, NCT, LOC | checkbox | Deduplicate the stream to avoid sending redundant data blocks. The destination system must also support deduplicated streams. See zfs(8). |
| Allow Blocks Larger than 128KB | SSH, NCT, LOC | checkbox | Allow sending large data blocks. The destination system must also support large blocks. See zfs(8). |
| Allow Compressed WRITE Records | SSH, NCT, LOC | checkbox | Use compressed WRITE records to make the stream more efficient. The destination system must also support compressed WRITE records. See zfs(8). |
| Number of retries for failed replications | SSH, NCT, LOC | integer | Number of times the replication is attempted before stopping and marking the task as failed. |
| Logging Level | All | drop-down menu | Message verbosity level in the replication task log. |
| Enabled | All | checkbox | Activates the replication schedule. |
8.6.3. Replication Tasks¶
Saved replications are shown on the Replication Tasks page.
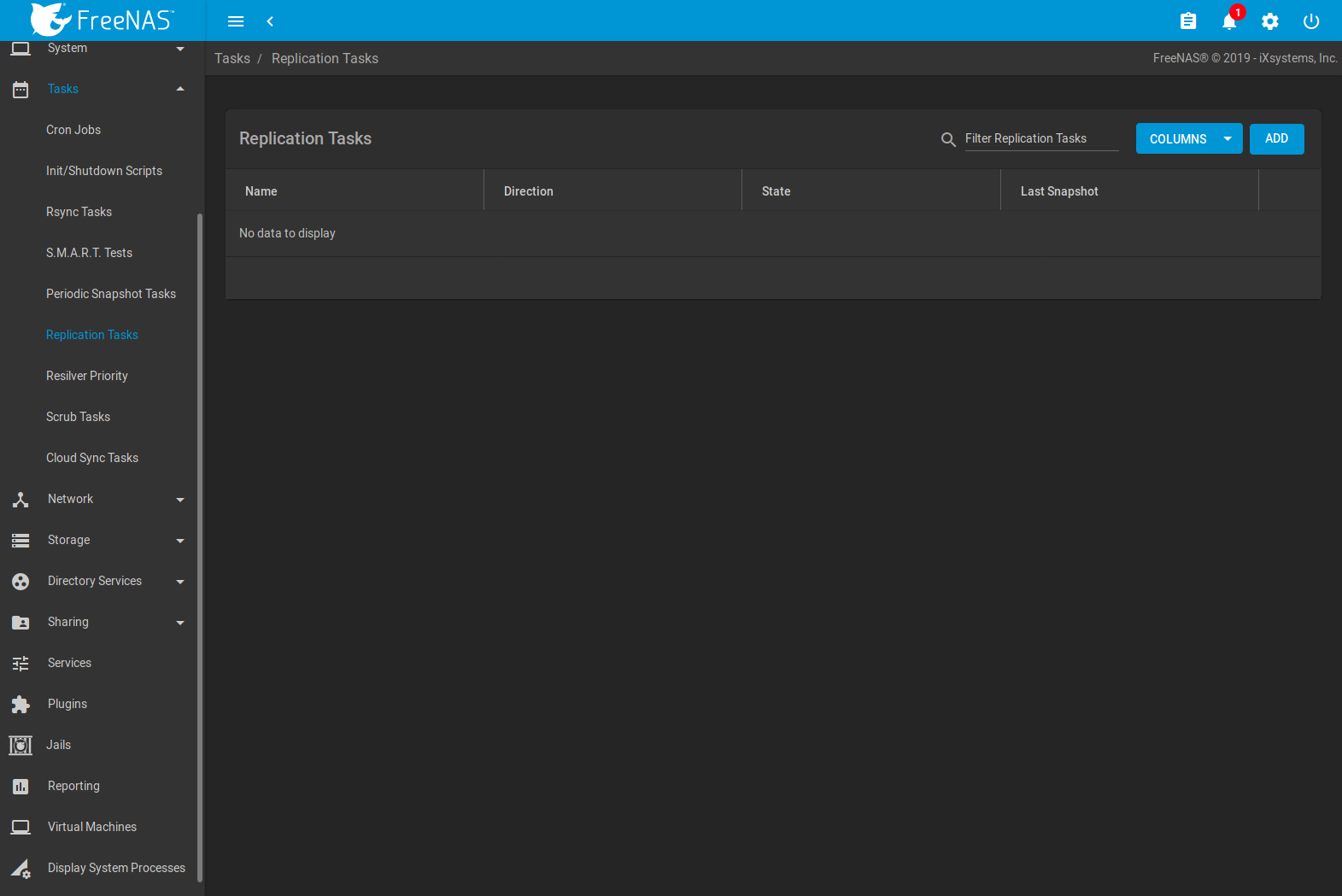
Fig. 8.6.4 Replication Task List
The replication name and configuration details are shown in the list. To adjust the default table view, open the COLUMNS menu and select the replication details to show in the normal table view.
The State column shows the status of the replication task. To view the detailed replication logs for a task, click the State entry when the task is running or finished.
Expanding an entry shows additional buttons for starting or editing a replication task.
8.6.4. Limiting Replication Times¶
The Schedule, Begin, and End times in a replication task make it possible to restrict when replication is allowed. These times can be set to only allow replication after business hours, or at other times when disk or network activity will not slow down other operations like snapshots or Scrub Tasks. The default settings allow replication to occur at any time.
These times control when replication task are allowed to start, but will not stop a replication task that is already running. Once a replication task has begun, it will run until finished.
8.6.5. Troubleshooting Replication¶
Replication depends on SSH, disks, network, compression, and encryption to work. A failure or misconfiguration of any of these can prevent successful replication.
Replication logs are saved in var/log/zettarepl.log. Logs of
individual replication tasks can be viewed by clicking the replication
State.
8.6.5.1. SSH¶
SSH must be able to connect from the source system to the destination system with an encryption key. This is tested from Shell by making an SSH connection from the source system to the destination system. For example, this is a connection from Alpha to Beta at 10.0.0.118. Start the Shell on the source machine (Alpha), then enter this command:
ssh -vv 10.0.0.118
On the first connection, the system might say
No matching host key fingerprint found in DNS.
Are you sure you want to continue connecting (yes/no)?
Verify that this is the correct destination computer from the
preceding information on the screen and type yes. At this
point, an SSH shell connection is open to the destination
system, Beta.
If a password is requested, SSH authentication is not working. An
SSH key value must be present in the destination system
/root/.ssh/authorized_keys file. /var/log/auth.log
file can show diagnostic errors for login problems on the destination
computer also.
8.6.5.2. Compression¶
Matching compression and decompression programs must be available on
both the source and destination computers. This is not a problem when
both computers are running FreeNAS®, but other operating systems might
not have lz4, pigz, or plzip compression programs installed by
default. An easy way to diagnose the problem is to set
Replication Stream Compression to Off. If the
replication runs, select the preferred compression method and check
/var/log/debug.log on the FreeNAS® system for errors.
8.6.5.3. Manual Testing¶
On Alpha, the source computer, the /var/log/messages file
can also show helpful messages to locate the problem.
On the source computer, Alpha, open a Shell and manually send
a single snapshot to the destination computer, Beta. The snapshot
used in this example is named auto-20161206.1110-2w. As
before, it is located in the alphapool/alphadata dataset. A
@ symbol separates the name of the dataset from the name of
the snapshot in the command.
zfs send alphapool/alphadata@auto-20161206.1110-2w | ssh 10.0.0.118 zfs recv betapool
If a snapshot of that name already exists on the destination computer, the system will refuse to overwrite it with the new snapshot. The existing snapshot on the destination computer can be deleted by opening a Shell on Beta and running this command:
zfs destroy -R betapool/alphadata@auto-20161206.1110-2w
Then send the snapshot manually again. Snapshots on the destination
system, Beta, are listed from the Shell with
zfs list -t snapshot or from
.
Error messages here can indicate any remaining problems.
8.7. Resilver Priority¶
Resilvering, or the process of copying data to a replacement disk, is best completed as quickly as possible. Increasing the priority of resilvers can help them to complete more quickly. The Resilver Priority menu makes it possible to increase the priority of resilvering at times where the additional I/O or CPU usage will not affect normal usage. Select to display the screen shown in Figure 8.7.1. Table 8.7.1 describes the fields on this screen.
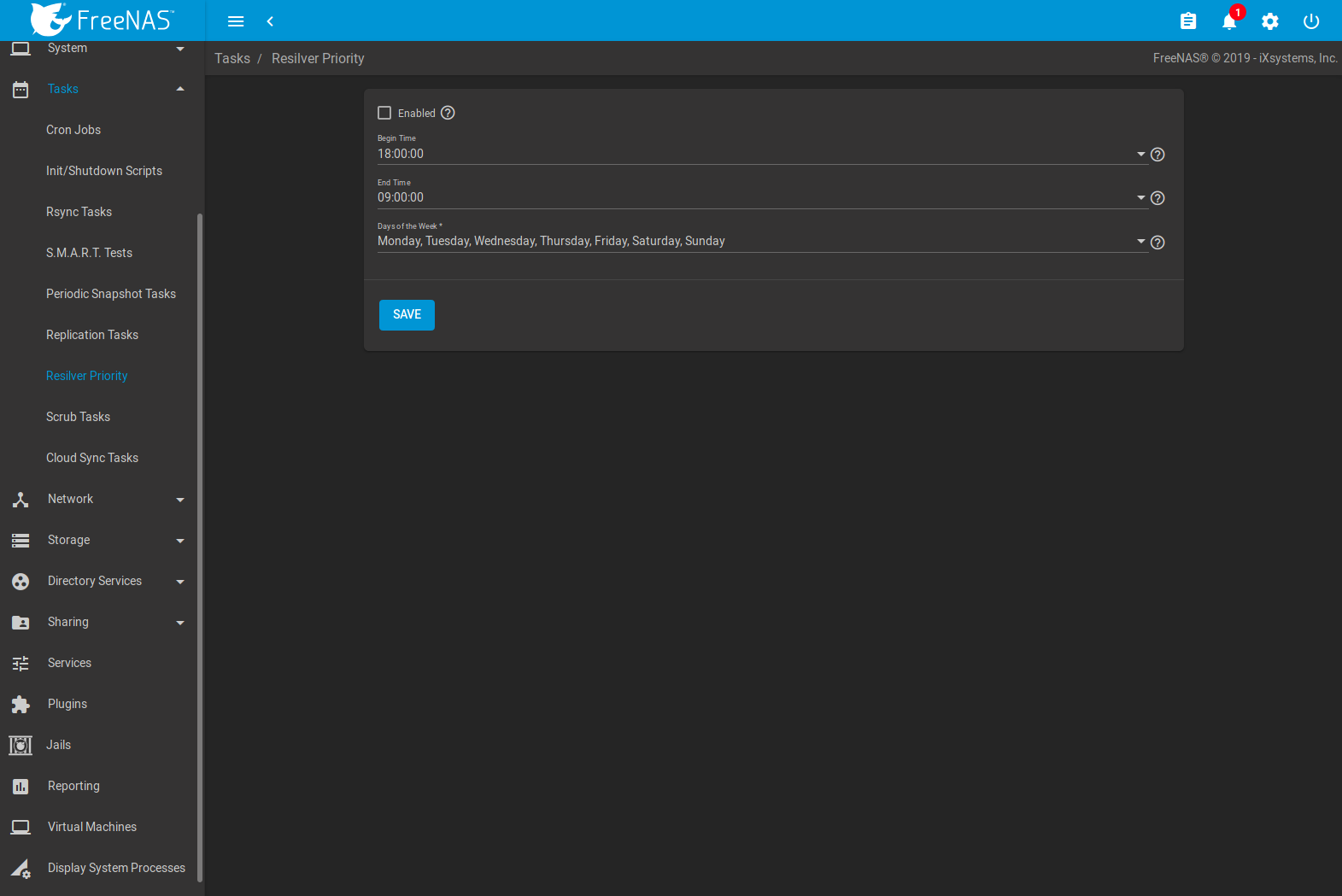
Fig. 8.7.1 Resilver Priority
| Setting | Value | Description |
|---|---|---|
| Enabled | checkbox | Set to run resilver tasks between the configured times. |
| Begin Time | drop-down | Choose the hour and minute when resilver tasks can be started. |
| End Time | drop-down | Choose the hour and minute when new resilver tasks can no longer be started. This does not affect active resilver tasks. |
| Days of the Week | checkboxes | Select the days to run resilver tasks. |
8.8. Scrub Tasks¶
A scrub is the process of ZFS scanning through the data on a pool. Scrubs help to identify data integrity problems, detect silent data corruptions caused by transient hardware issues, and provide early alerts of impending disk failures. FreeNAS® makes it easy to schedule periodic automatic scrubs.
It is recommneded that each pool is scrubbed at least once a month. Bit errors in critical data can be detected by ZFS, but only when that data is read. Scheduled scrubs can find bit errors in rarely-read data. The amount of time needed for a scrub is proportional to the quantity of data on the pool. Typical scrubs take several hours or longer.
The scrub process is I/O intensive and can negatively impact performance. Schedule scrubs for evenings or weekends to minimize impact to users. Make certain that scrubs and other disk-intensive activity like S.M.A.R.T. Tests are scheduled to run on different days to avoid disk contention and extreme performance impacts.
Scrubs only check used disk space. To check unused disk space, schedule S.M.A.R.T. Tests of Type Long Self-Test to run once or twice a month.
Scrubs are scheduled and managed with .
When a pool is created, a scrub is automatically scheduled. An entry
with the same pool name is added to
.
A summary of this entry can be viewed with
.
Figure 8.8.1
displays the default settings for the pool named pool1. In
this example, (Options) and Edit for a pool is clicked to
display the Edit screen.
Table 8.8.1 summarizes the options in this
screen.
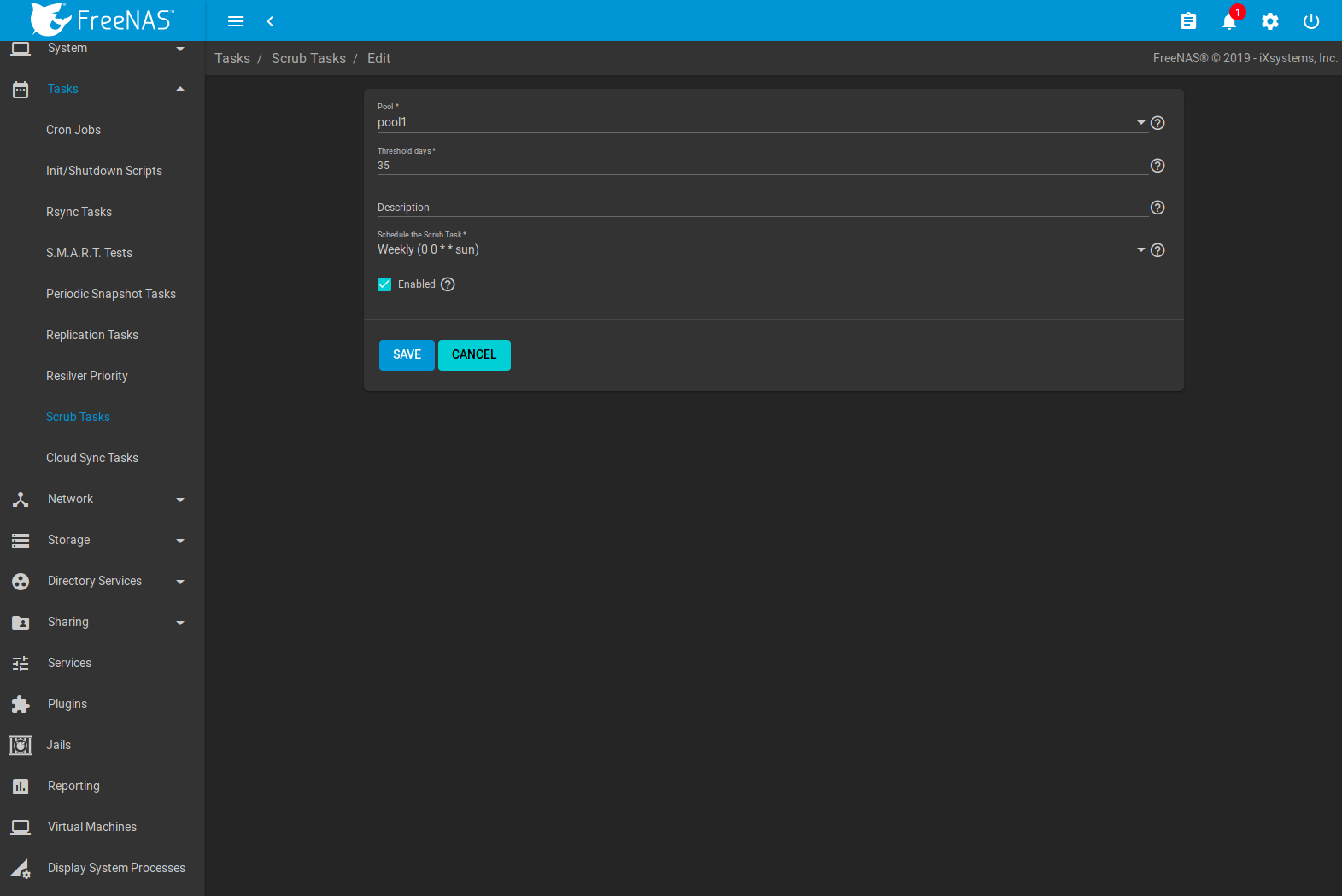
Fig. 8.8.1 Viewing Pool Default Scrub Settings
| Setting | Value | Description |
|---|---|---|
| Pool | drop-down menu | Choose a pool to scrub. |
| Threshold days | string | Days before a completed scrub is allowed to run again. This controls the task schedule. For example, scheduling a scrub to run daily and setting Threshold days to 7 means the scrub attempts to run daily. When the scrub is successful, it continues to check daily but does not run again until seven days have elapsed. Using a multiple of seven ensures the scrub always occurs on the same weekday. |
| Description | string | Describe the scrub task. |
| Schedule the Scrub Task | drop-down menu | Choose how often to run the scrub task. Choices are Hourly, Daily, Weekly, Monthly, or Custom. Selecting Custom opens the Advanced Scheduler. |
| Enabled | checkbox | Unset to disable the scheduled scrub without deleting it. |
Review the default selections and, if necessary, modify them to meet the needs of the environment. Scrub tasks cannot run for locked or unmounted pools.
Scheduled scrubs can be deleted with the Delete button, but this is not recommended. Scrubs can provide an early indication of disk issues before a disk failure. If a scrub is too intensive for the hardware, consider temporarily deselecting the Enabled button for the scrub until the hardware can be upgraded.
8.9. Cloud Sync Tasks¶
Files or directories can be synchronized to remote cloud storage providers with the Cloud Sync Tasks feature.
Warning
This Cloud Sync task might go to a third party commercial vendor not directly affiliated with iXsystems. Please investigate and fully understand that vendor’s pricing policies and services before creating any Cloud Sync task. iXsystems is not responsible for any charges incurred from the use of third party vendors with the Cloud Sync feature.
Cloud Credentials must be defined before a cloud sync is created. One set of credentials can be used for more than one cloud sync. For example, a single set of credentials for Amazon S3 can be used for separate cloud syncs that push different sets of files or directories.
A cloud storage area must also exist. With Amazon S3, these are called buckets. The bucket must be created before a sync task can be created.
After the cloud credentials have been configured, is used to define the schedule for running a cloud sync task. The time selected is when the Cloud Sync task is allowed to begin. An in-progress cloud sync must complete before another cloud sync can start. The cloud sync runs until finished, even after the selected ending time. To stop the cloud sync task before it is finished, click (Options) .
An example is shown in Figure 8.9.1.
Fig. 8.9.1 Cloud Sync Status
The cloud sync Status indicates the state of most recent cloud sync. Clicking the Status entry shows the task logs and includes an option to download them.
Click ADD to display the Add Cloud Sync menu shown in Figure 8.9.2.
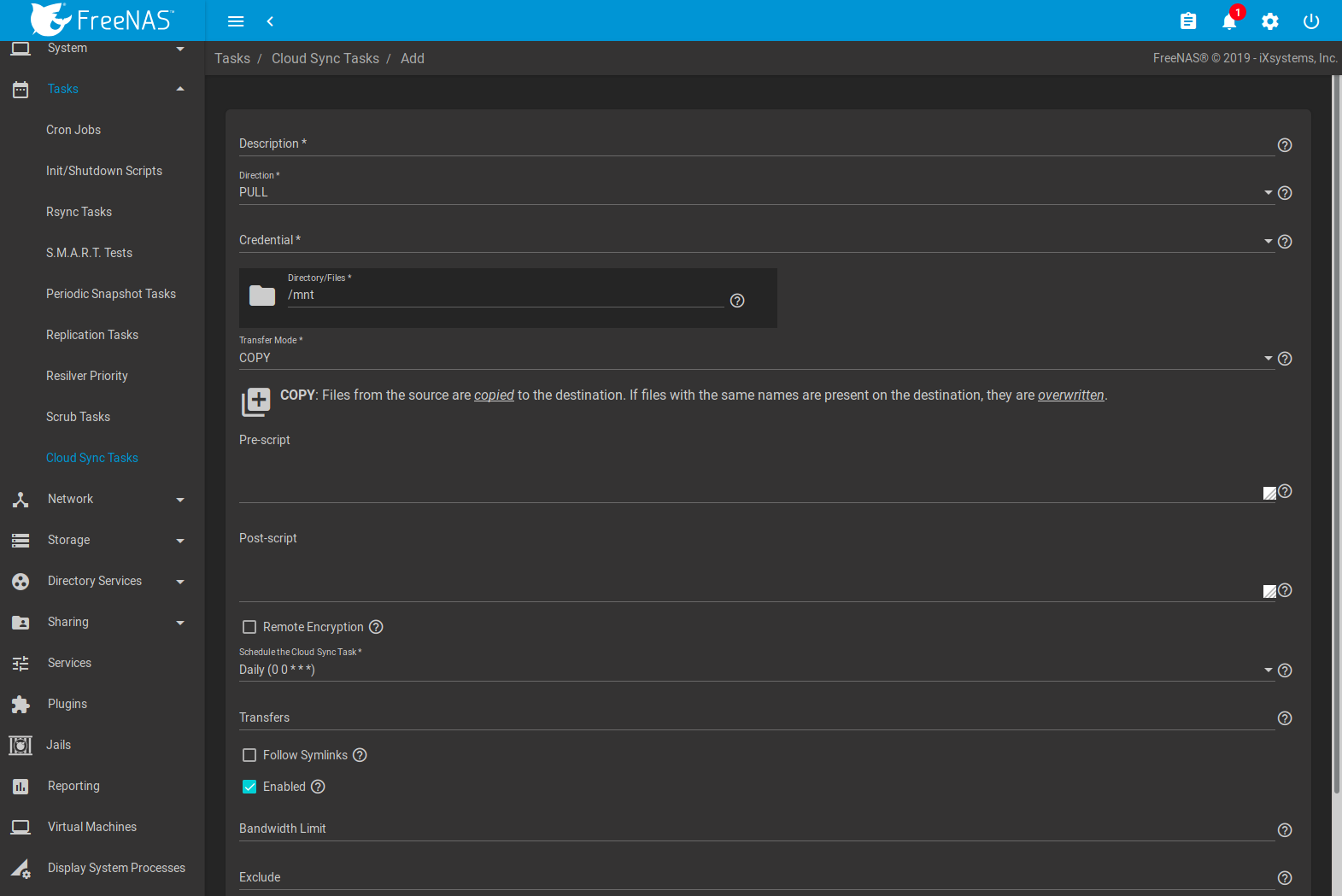
Fig. 8.9.2 Adding a Cloud Sync
Table 8.9.1 shows the configuration options for Cloud Syncs.
| Setting | Value Type | Description |
|---|---|---|
| Description | string | A description of the Cloud Sync Task. |
| Direction | drop-down menu | PUSH sends data to cloud storage. PULL receives data from cloud storage. |
| Credential | drop-down menu | Select the cloud storage provider credentials from the list of available Cloud Credentials. The credential is tested and an error is displayed if a connection cannot be made. Click Fix Credential to go to the configuration page for that Cloud Credential. SAVE is disabled until a valid credential is selected. |
| Bucket/Container | drop-down menu | Bucket: Only appears when an S3 credential is the Provider. Select the predefined S3 bucket to use. Container: The pre-configured container name. Only appears when a |
| Folder | browse button | The name of the predefined folder within the selected bucket or container. Type the name or click (Browse) to list the remote filesystem and choose the folder. |
| Server Side Encryption | drop-down menu | Active encryption on the cloud provider account. Choose None or AES-256. Only visible when the cloud provider supports encryption. |
| Storage Class | drop-down menu | Classification for each S3 object. Choose a class based on the specific use case or performance requirements. See Amazon S3 Storage Classes for more information on which storage class to choose. Storage Class only appears when an S3 credential is the Provider. |
| Upload Chunk Size (MiB) | integer | Files are split into chunks of this size before upload. Only appears with a (B2) Credential. The number of chunks that can be simultaneously transferred is set by the Transfers number. The single largest file being transferred must fit into no more than 10,000 chunks. |
| Use –fast-list | checkbox | Use fewer transactions in exchange for more RAM. Modifying this setting can speed up or slow down the transfer. Only appears with a compatible Credential. |
| Directory/Files | browse button | Select directories or files to be sent to the cloud for Push syncs, or the destination to be written for Pull syncs. Be cautious about the destination of Pull jobs to avoid overwriting existing files. |
| Transfer Mode | drop-down menu | SYNC: Files on the destination are changed to match those on the source. If a file does not exist on the source, it is also deleted from the destination. There are exceptions to this behavior. COPY: Files from the source are copied to the destination. If files with the same names are present on the destination, they are overwritten. MOVE: After files are copied from the source to the destination, they are deleted from the source. Files with the same names on the destination are overwritten. |
| Take Snapshot | checkbox | Take a snapshot of the dataset before a PUSH. |
| Pre-script | string | A script to execute before the Cloud Sync Task is run. |
| Post-script | string | A script to execute after the Cloud Sync Task is run. |
| Remote Encryption | checkbox | Use rclone crypt to manage data encryption during PUSH or PULL transfers: PUSH: Encrypt files before transfer and store the encrypted files on the remote system. Files are encrypted using the Encryption Password and Encryption Salt values. PULL: Decrypt files that are being stored on the remote system before the transfer. Transferring the encrypted files requires entering the same Encryption Password and Encryption Salt that was used to encrypt the files. Adds the Filename Encryption, Encryption Password, and Encryption Salt options. Additional details about the encryption algorithm and key derivation are available in the rclone crypt File formats documentation. |
| Filename Encryption | checkbox | Encrypt (PUSH) or decrypt (PULL) file names with the rclone “Standard” file name encryption mode. The original directory structure is preserved. A filename with the same name always has the same encrypted filename. PULL tasks that have Filename Encryption enabled and an incorrect Encryption Password or Encryption Salt will not transfer any files but still report that the task was successful. To verify that files were transferred successfully, click the finished task status to see a list of transferred files. |
| Encryption Password | string | Password to encrypt and decrypt remote data. Warning: Always securely back up this password! Losing the encryption password will result in data loss. |
| Encryption Salt | string | Enter a long string of random characters for use as salt for the encryption password. Warning: Always securely back up the encryption salt value! Losing the salt value will result in data loss. |
| Schedule the Cloud Sync Task | drop-down menu | Choose how often or at what time to start a sync. Choices are Hourly, Daily, Weekly, Monthly, or Custom. Selecting Custom opens the Advanced Scheduler. |
| Transfers | integer | Number of simultaneous file transfers. Enter a number based on the available bandwidth and destination system performance. See rclone –transfers. |
| Follow Symlinks | checkbox | Include symbolic link targets in the transfer. |
| Enabled | checkbox | Enable this Cloud Sync Task. Unset to disable this Cloud Sync Task without deleting it. |
| Bandwidth Limit | string | Restrict the data transfer rate of this task. Enter either a single bandwidth limit or a bandwidth limit schedule in rclone format. Rate limitations are in bytes/second, not bits/second. The default unit is kilobytes. Example: “08:00,512 12:00,10M 13:00,512 18:00,30M 23:00,off”. |
| Exclude | string | List of files and directories to exclude from sync, one per line. See https://rclone.org/filtering/. |
There are specific circumstances where a SYNC task does not delete files from the destination:
- If rclone sync encounters any errors, files are not deleted in the destination. This includes a common error when the Dropbox copyright detector flags a file as copyrighted.
- Syncing to a B2 bucket does not delete files from the bucket, even when those files have been deleted locally. Instead, files are tagged with a version number or moved to a hidden state. To automatically delete old or unwanted files from the bucket, adjust the Backblaze B2 Lifecycle Rules
To modify an existing cloud sync, click (Options) to access the Run Now, Edit, and Delete options.
8.9.1. Cloud Sync Example¶
This example shows a Push cloud sync which writes an accounting department backup file from the FreeNAS® system to Amazon S3 storage.
Before the new cloud sync was added, a bucket called cloudsync-bucket was created with the Amazon S3 web console for storing data from the FreeNAS® system.
Click and ADD to enter the credentials for storage on an Amazon AWS account. The credential is given the name S3 Storage, as shown in Figure 8.9.3:
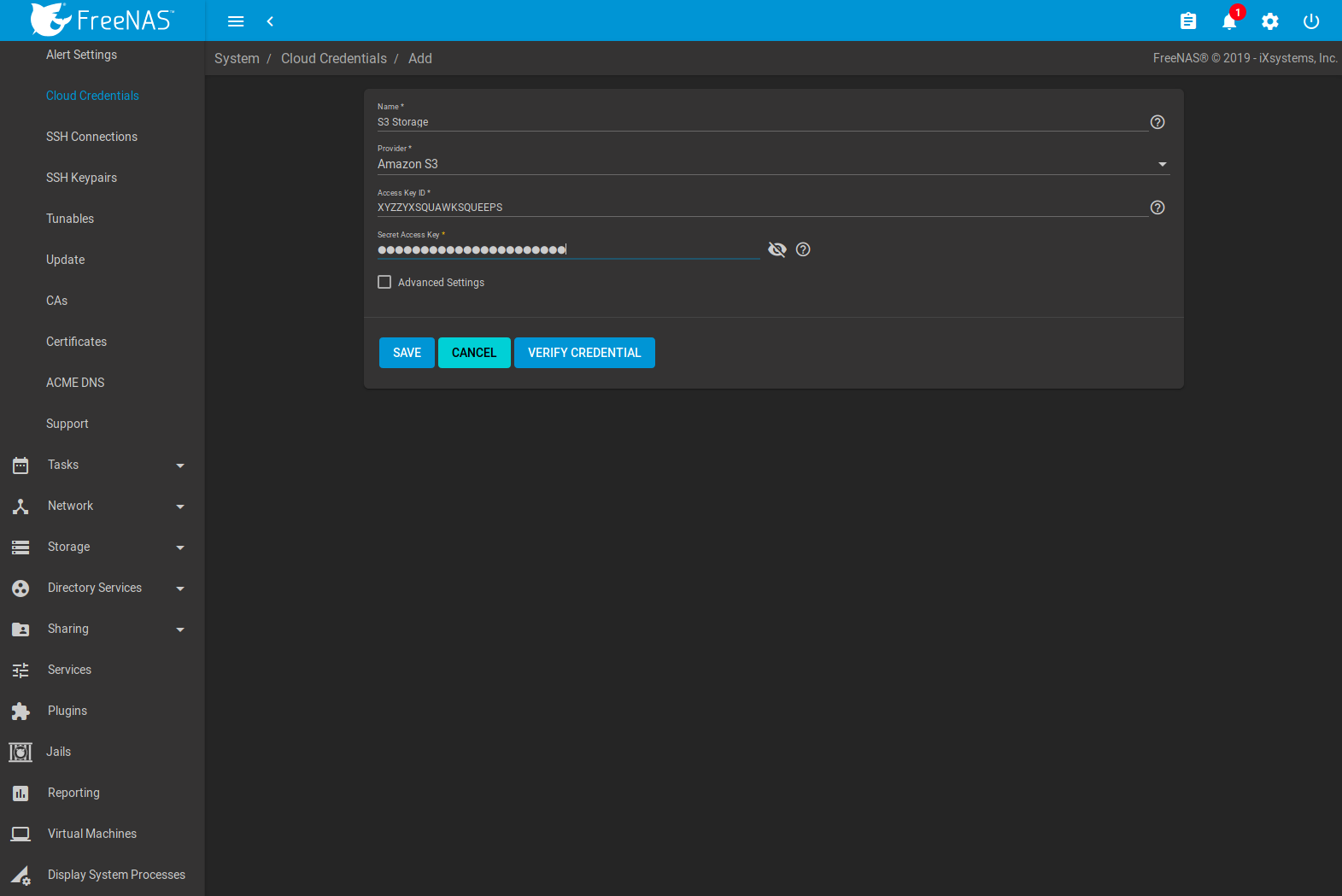
Fig. 8.9.3 Example: Adding Cloud Credentials
The local data to be sent to the cloud is a single file called
accounting-backup.bin on the smb-storage dataset.
Click and ADD to create a cloud sync job. The Description is set to backup-acctg to describe the job. This data is being sent to cloud storage, so this is a Push. The provider comes from the cloud credentials defined in the previous step, and the destination bucket cloudsync-bucket has been chosen.
The Directory/Files is adjusted to the data file.
The remaining fields are for setting a schedule. The default is to send the data to cloud storage once an hour, every day. The options provide great versatility in configuring when a cloud sync runs, anywhere from once a minute to once a year.
The Enabled field is enabled by default, so this cloud sync will run at the next scheduled time.
The completed dialog is shown in Figure 8.9.4:
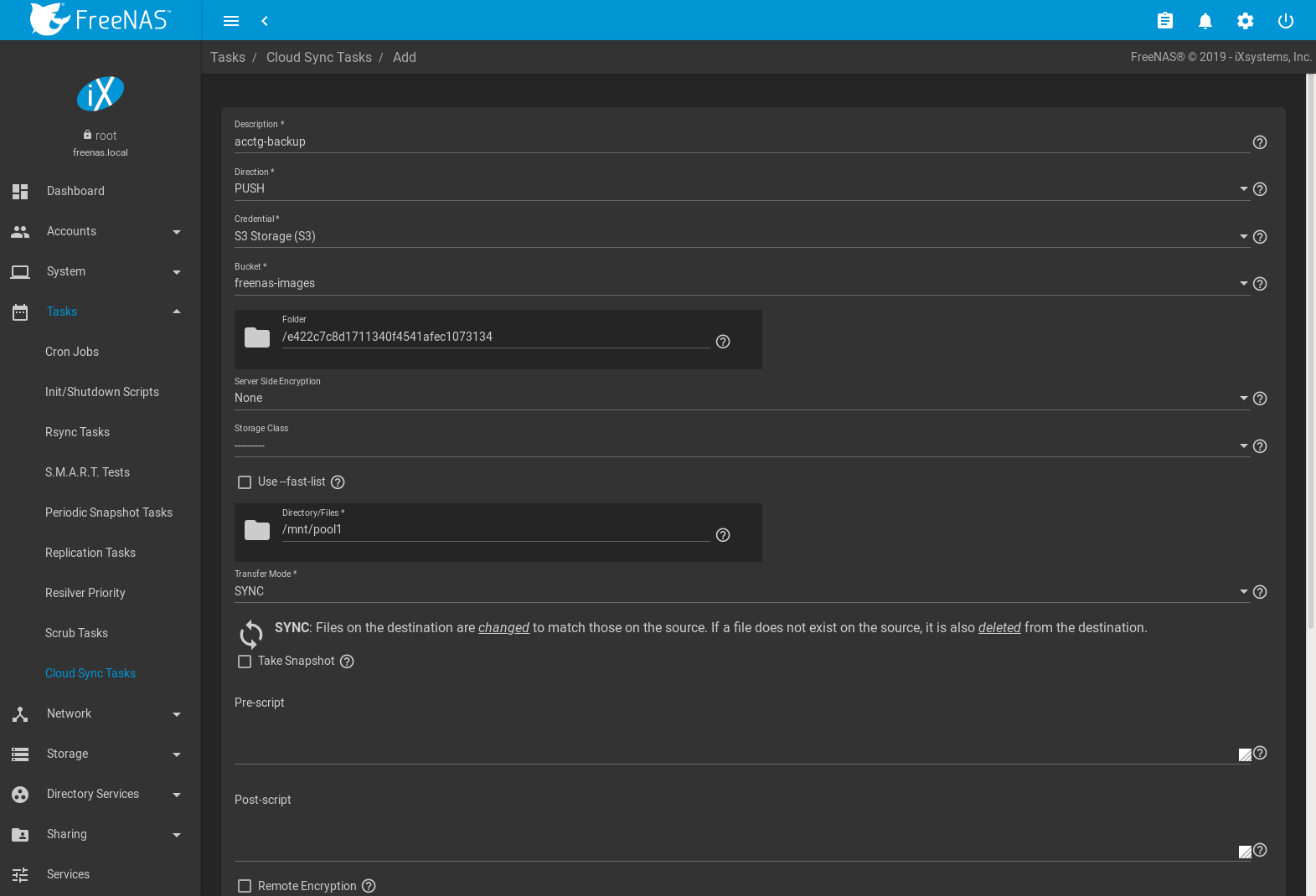
Fig. 8.9.4 Example: Adding a Cloud Sync