ctag
Patron
- Joined
- Jun 16, 2017
- Messages
- 225
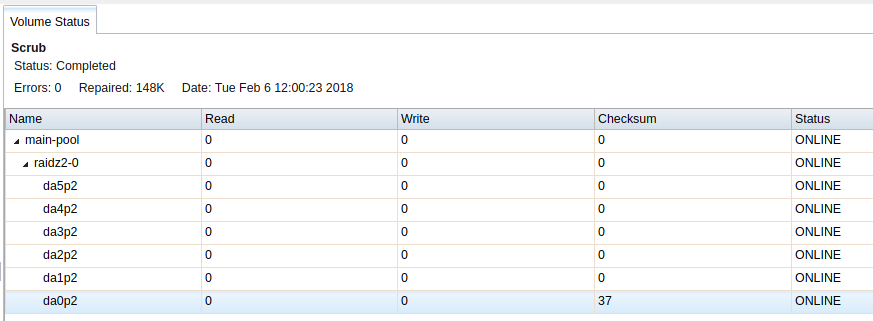
Hrm, the host doesn't have any sleep mode or anything. I was about to try returning the drive today (at the risk of replacing it with a different model once shucked) and noticed that all three drives failed the extended SMART tests... Something weird is going on.
I ran a system update on the host, rebooted it, and then plugged one of the drives back in and started an extended test, and it failed a little while later just like before:
I ran a system update on the host, rebooted it, and then plugged one of the drives back in and started an extended test, and it failed a little while later just like before:
Code:
SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Aborted by host 90% 190 - # 2 Short offline Completed without error 00% 189 - # 3 Extended offline Aborted by host 80% 162 - # 4 Short offline Completed without error 00% 161 - # 5 Extended offline Aborted by host 90% 23 - # 6 Short offline Completed without error 00% 22 - # 7 Extended offline Aborted by host 80% 1 - # 8 Short offline Completed without error 00% 0 -