
Sawtaytoes
Patron
- Joined
- Jul 9, 2022
- Messages
- 221
All of a sudden, my NAS started restarting randomly tonight.
I'm running TrueNAS SCALE 23.
---
SKIP TO https://www.truenas.com/community/threads/truenas-keeps-restarting-every-6-10-min.114668/post-795150. I summarize and detail everything there.
Leaving the rest of this post for historical purposes.
---
I think it's a power-related issue because it doesn't appear to shut down; it only starts up again randomly.
I tested a bunch of things, but I'm wondering if I've overloaded the +5V rail on my PSUs in some way.
Logs
It looks like it's been happening quite a few times tonight, and only the startup is logged. That makes me think it's a hardware issue:
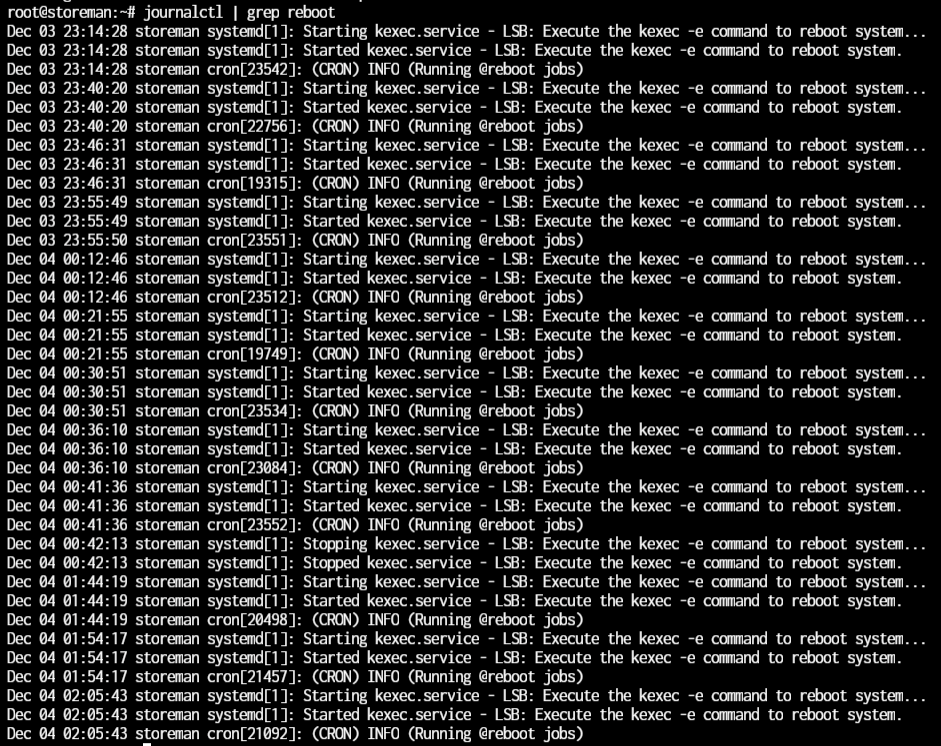
I went ahead and shut down the server for tonight to avoid any other issues.
Why SSDs?
I used to have 68 SSDs in this NAS until a month ago when I started got an upgrade to swap the 60 hot-swap bays for 128 hot-swap bays.
During this upgrade, I found that I was missing 2 power connectors, so I only plugged in 96 drives.
After talking to the chassis manufacturer, I found out my NAS wasn't in a supported configuration and that it shouldn't even be working because the PSU only has 50A of +5V power. I later found out it worked only because it evenly distributes the power draw between both PSUs effectively giving me 100A of +5V power so long as I don't care about having redundant PSUs.
Even though I had 96 SSDs installed, I was only using 80 of them until I switch this over to dRAID with all 128 drives, but that requires some +5V offloading which I'm going to do soon, but haven't yet done. The other night, I removed of those 15 unused drives, so only 1 remains. That puts me at 81 SSDs in this system.
All but 6 of my SSDs are Crucial MX500 drives which are rated at 1.7A on the back (138A on the +5V rail if they actually used 1.7A), but the power draw from my PSUs, even the peak readings, have never gone over a rough estimate of 0.8A per drive. I left my NAS in this configuration until I had time to offload the +5V rail.
I have a solution for this +5V rail problem, but my dad was gonna help me out and couldn't make it this weekend.
The Issue Begins
Tonight, I was copying some data from my main rig to my NAS (to the SSD zpool), and suddenly, I lost connection. That's because it restarted. And then, it happened again, and again, and again every 6-10 minutes or so.
I checked a bunch of things like:
The peak power draw numbers, even with all the drives in my NAS, were nowhere near the values I've seen during a scrub on this zpool. They also went down 40% from 470W to 290W after pulling those 48 drives. That's about 3.75W per drive (0.75A of +5V).
This is the reported wattage with the system powered off:

Not sure whats going on there. The system is OFF.
Looking at the power draw over the last 6 hours when this started, I actually pulled 48 SSDs out and while the average power draw decreated, the peak power draw doesn't look like it changed at all:

Just to be clear, the system really is powered off:


I also checked the temps on my CPU and other hardware from the motherboard's IPMI panel. Everything seems in order. Processor is at 60C idle, but it's a 16-core Epyc with a half-height cooler and a single 60mm Noctua fan. I don't think 60C would force a reboot considering processors tend to throttle around 90-100C.
The IPMI web app also doesn't report any logs other than the fans spinning down, but those errors have shown for over a year even with an ASRock Rack motherboard.

Please Help!
Even after all these checks and changes, I still had the same restarting issue.
Now I'm wondering if it's something else.
Is there a good way to check what might be going on?
UPDATE
At this point, I've determined it's certain SAS ports on 1 or more of the SAS controllers causing the problem. I'm 95% certain this is the issue.
I'm running TrueNAS SCALE 23.
---
SKIP TO https://www.truenas.com/community/threads/truenas-keeps-restarting-every-6-10-min.114668/post-795150. I summarize and detail everything there.
Leaving the rest of this post for historical purposes.
---
I think it's a power-related issue because it doesn't appear to shut down; it only starts up again randomly.
I tested a bunch of things, but I'm wondering if I've overloaded the +5V rail on my PSUs in some way.
Logs
It looks like it's been happening quite a few times tonight, and only the startup is logged. That makes me think it's a hardware issue:
I went ahead and shut down the server for tonight to avoid any other issues.
Why SSDs?
I used to have 68 SSDs in this NAS until a month ago when I started got an upgrade to swap the 60 hot-swap bays for 128 hot-swap bays.
During this upgrade, I found that I was missing 2 power connectors, so I only plugged in 96 drives.
After talking to the chassis manufacturer, I found out my NAS wasn't in a supported configuration and that it shouldn't even be working because the PSU only has 50A of +5V power. I later found out it worked only because it evenly distributes the power draw between both PSUs effectively giving me 100A of +5V power so long as I don't care about having redundant PSUs.
Even though I had 96 SSDs installed, I was only using 80 of them until I switch this over to dRAID with all 128 drives, but that requires some +5V offloading which I'm going to do soon, but haven't yet done. The other night, I removed of those 15 unused drives, so only 1 remains. That puts me at 81 SSDs in this system.
All but 6 of my SSDs are Crucial MX500 drives which are rated at 1.7A on the back (138A on the +5V rail if they actually used 1.7A), but the power draw from my PSUs, even the peak readings, have never gone over a rough estimate of 0.8A per drive. I left my NAS in this configuration until I had time to offload the +5V rail.
I have a solution for this +5V rail problem, but my dad was gonna help me out and couldn't make it this weekend.
The Issue Begins
Tonight, I was copying some data from my main rig to my NAS (to the SSD zpool), and suddenly, I lost connection. That's because it restarted. And then, it happened again, and again, and again every 6-10 minutes or so.
I checked a bunch of things like:
- Unplugging the UPS USB cables from the NAS.
- Plugging each PSU into a different UPS.
- Pulling 48 SSDs into two separate 24-drive rackmount cases I bought in case the +5V offloading idea failed.
- Turning off any SSD snapshot backup tasks; although, I left the hourly snapshot task running.
The peak power draw numbers, even with all the drives in my NAS, were nowhere near the values I've seen during a scrub on this zpool. They also went down 40% from 470W to 290W after pulling those 48 drives. That's about 3.75W per drive (0.75A of +5V).
This is the reported wattage with the system powered off:
Not sure whats going on there. The system is OFF.
Looking at the power draw over the last 6 hours when this started, I actually pulled 48 SSDs out and while the average power draw decreated, the peak power draw doesn't look like it changed at all:
Just to be clear, the system really is powered off:
I also checked the temps on my CPU and other hardware from the motherboard's IPMI panel. Everything seems in order. Processor is at 60C idle, but it's a 16-core Epyc with a half-height cooler and a single 60mm Noctua fan. I don't think 60C would force a reboot considering processors tend to throttle around 90-100C.
The IPMI web app also doesn't report any logs other than the fans spinning down, but those errors have shown for over a year even with an ASRock Rack motherboard.
Please Help!
Even after all these checks and changes, I still had the same restarting issue.
Now I'm wondering if it's something else.
Is there a good way to check what might be going on?
UPDATE
At this point, I've determined it's certain SAS ports on 1 or more of the SAS controllers causing the problem. I'm 95% certain this is the issue.
Last edited:

