Richard Durso
Explorer
- Joined
- Jan 30, 2014
- Messages
- 70
I've been using FreeNAS since early 9.x releases and has always been incredibly stable. I recently upgraded to FreeNAS 11.2 and upgraded my four WD RED 4TB drives to WD 6TB drives -- one by one over course of a month, removed, replaced, re silvered, no problems until the last drive was replaced. I've had nothing but problems since.
Performance is very slow - I don't know how to quantify this other than saving files which use to be instant now takes 15 seconds to come back (small 3.5MB files). This is very low usage home server, I'm the only user on it. I've started to get random reboot messages:
And I've started to get panic messages:
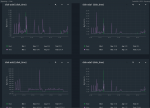
The device in question ADA2 is also showing very slow "disk time" on the Reports Dashboards. See attached image.
I'm not sure how to troubleshoot this. My zpool status looks perfect (see attached image).
Performance is very slow - I don't know how to quantify this other than saving files which use to be instant now takes 15 seconds to come back (small 3.5MB files). This is very low usage home server, I'm the only user on it. I've started to get random reboot messages:
Code:
freenas.localdomain had an unscheduled system reboot. The operating system successfully came back online at Thu Jun 6 12:47:33 2
And I've started to get panic messages:
Code:
freenas.localdomain kernel log messages: > panic: I/O to pool 'main' appears to be hung on vdev guid 2342498213395394601 at '/dev/gptid/85d67320-72b1-11e9-9ae5-002590dd15dd'. > cpuid = 3 > KDB: stack backtrace: > db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe083c98d800 > vpanic() at vpanic+0x177/frame 0xfffffe083c98d860 > panic() at panic+0x43/frame 0xfffffe083c98d8c0 > vdev_deadman() at vdev_deadman+0x191/frame 0xfffffe083c98d910 > vdev_deadman() at vdev_deadman+0x41/frame 0xfffffe083c98d960 > vdev_deadman() at vdev_deadman+0x41/frame 0xfffffe083c98d9b0 > spa_deadman() at spa_deadman+0x87/frame 0xfffffe083c98d9e0 > taskqueue_run_locked() at taskqueue_run_locked+0x154/frame 0xfffffe083c98da40 > taskqueue_thread_loop() at taskqueue_thread_loop+0x98/frame 0xfffffe083c98da70 > fork_exit() at fork_exit+0x83/frame 0xfffffe083c98dab0 > fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe083c98dab0 > --- trap 0, rip = 0, rsp = 0, rbp = 0 --- > KDB: enter: panic > Copyright (c) 1992-2018 The FreeBSD Project. > Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994 > The Regents of the University of California. All rights reserved. > FreeBSD is a registered trademark of The FreeBSD Foundation. > FreeBSD 11.2-STABLE #0 r325575+95cc58ca2a0(HEAD): Fri May 10 15:57:35 EDT 2019
The device in question ADA2 is also showing very slow "disk time" on the Reports Dashboards. See attached image.
I'm not sure how to troubleshoot this. My zpool status looks perfect (see attached image).