Fraoch
Patron
- Joined
- Aug 14, 2014
- Messages
- 395
I've been testing my server. It's been working great so far but it looks like I broke something in the OS.
I can no longer boot.
I was stressing my drives using @jgreco 's test here:
https://forums.freenas.org/index.ph...esting-your-freenas-system.17750/#post-148773
It was working well but overnight my main machine kicked off an rsync backup to FreeNAS.
I get up this morning and my main machine is locked into IOwait. The FreeNAS web page isn't responding anymore and I can't ssh in. I try to power FreeNAS down via IPMI and IPMI reports back that this failed because the operating system is taking too long. I then send a reset signal, which worked.
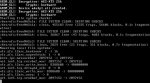
I get the console up while it's rebooting. It reports the file system is clean but gets stuck at the following (see attachment).
It looks like it's hanging at a tunable added using Autotune? Should I unset all tunables as described in the manual? Autotune has never caused a problem before, I'm wondering why it is now.
Thanks for any help or advice!
I can no longer boot.
I was stressing my drives using @jgreco 's test here:
https://forums.freenas.org/index.ph...esting-your-freenas-system.17750/#post-148773
It was working well but overnight my main machine kicked off an rsync backup to FreeNAS.
I get up this morning and my main machine is locked into IOwait. The FreeNAS web page isn't responding anymore and I can't ssh in. I try to power FreeNAS down via IPMI and IPMI reports back that this failed because the operating system is taking too long. I then send a reset signal, which worked.
I get the console up while it's rebooting. It reports the file system is clean but gets stuck at the following (see attachment).
It looks like it's hanging at a tunable added using Autotune? Should I unset all tunables as described in the manual? Autotune has never caused a problem before, I'm wondering why it is now.
Thanks for any help or advice!