Hi, I am looking for help regarding the state of my pool and how can I fix it.
So for the context. For some months now I had a problem with my pool, or specifically the Toshiba P300 3TB drives. They were either getting kicked out of the pool or I saw that they had high SEEK_ERROR_RATE flag in SMART. I was sending and replacing them on warranty claim (Toshiba accepted every warranty claim and either sent a refund or a new drive). I didn't have any problems when my pool was 6 x 1TB drives in Raid-z2. The problems started happening when I went 6 x 3 TB drives.
So I thought at first that it is a problem with a hardware, either this 3 TB Toshiba drives were bad or sata cables were problematic. So I bought 2 WD RED Pro 4 TB drives and added them to my pool, as a first step of fully replacing Toshiba drives (WD are 2x the cost so I couldn't do all at once). I also started replacing SATa cable every time I had to switch drive to new one.
Then I started getting this errors:
.JPG")
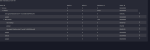
I even opened bug ticket as I thought it is software error, rather than hardware one. I got a response to check all sata cables, unplug and plug them. This is when I got unrecoverable errors. After I mixed, unplugged and plugged in the sata cables to drives and boot up the machine I almost lost the pool. It went from healthy to degradaded with 2 drives removed from the pool. I replaced one, but WD drive was getting kicked out of the pool. So I replaced it with new Toshiba P300 drive I got from warranty claim and same errors happended. The drive was kicked out of the pool as well:

I am just not sure what to do anymore. It doesn't look like hardware error anymore to me, at least when it comes to drives and sata cables. This was brand new Toshiba drive removed, with new sata cable. I don't think I can be that unlucky in terms of drives, from 2 separate vendors. This is what GUI is showing up:

Do you have any ideas how can i troubleshoot it and make my pool healthy again? I know I can't fix the unrecoverable error (I had to delete snapshots, also wanted to change whenthey are done and forgot about it, my mistake I know) but I want to prevent future errors. I am suspecting maybe MOBO has some problems with that drives? They are all connected to SATA ports on MOBO. I am thinking on buying HBA card and connecting the drives to it. Do you think it might help?
My mobo is: Asrock e3v5 ws
Processor: intel pentium g4560
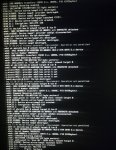
I am pasting zpool status as well:
Warning: settings changed through the CLI are not written to
the configuration database and will be reset on reboot.
root@freenas:~ # zpool status -v\
?
pool: chmura
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: scrub repaired 0 in 0 days 01:57:51 with 8 errors on Sun Sep 20 04:16:22 2020
config:
NAME STATE READ WRITE CKSUM
chmura DEGRADED 0 0 15.0K
raidz2-0 DEGRADED 0 0 60.0K
867640655208291443 UNAVAIL 0 0 0 was /dev/gptid/00bb206d-da79-11ea-bd48-d050999ece98
gptid/900cbecd-4c3a-11ea-9c4f-d050999ece98 DEGRADED 0 0 0 too many errors
replacing-2 DEGRADED 0 0 1.69K
4969840580276665161 REMOVED 0 0 0 was /dev/ada0p2
gptid/5e6de3ca-f6e0-11ea-8d13-d050999ece98 ONLINE 0 0 0
8319921696860204576 REMOVED 0 0 0 was /dev/gptid/9f4e4fea-fabd-11ea-8d13-d050999ece98
gptid/6ba25256-beeb-11ea-92c2-d050999ece98 DEGRADED 0 0 0 too many errors
gptid/233769e6-54d2-11ea-be8d-d050999ece98 DEGRADED 0 0 0 too many errors
gptid/147d9872-a728-11ea-a173-d050999ece98 DEGRADED 0 0 0 too many errors
errors: Permanent errors have been detected in the following files:
<metadata>:<0x8b>
<metadata>:<0x95>
<metadata>:<0x398>
<metadata>:<0x9b>
<metadata>:<0xb0>
<metadata>:<0xb3>
chmura/iocage/jails/chmurka3/root@ioc_update_11.3-RELEASE-p6_2020-09-15_02-26-28:<0x0>
pool: freenas-boot
state: ONLINE
scan: scrub repaired 0 in 0 days 00:02:10 with 0 errors on Wed Sep 16 03:47:10 2020
config:
Can you please share your thoughts on this?
So for the context. For some months now I had a problem with my pool, or specifically the Toshiba P300 3TB drives. They were either getting kicked out of the pool or I saw that they had high SEEK_ERROR_RATE flag in SMART. I was sending and replacing them on warranty claim (Toshiba accepted every warranty claim and either sent a refund or a new drive). I didn't have any problems when my pool was 6 x 1TB drives in Raid-z2. The problems started happening when I went 6 x 3 TB drives.
So I thought at first that it is a problem with a hardware, either this 3 TB Toshiba drives were bad or sata cables were problematic. So I bought 2 WD RED Pro 4 TB drives and added them to my pool, as a first step of fully replacing Toshiba drives (WD are 2x the cost so I couldn't do all at once). I also started replacing SATa cable every time I had to switch drive to new one.
Then I started getting this errors:
I even opened bug ticket as I thought it is software error, rather than hardware one. I got a response to check all sata cables, unplug and plug them. This is when I got unrecoverable errors. After I mixed, unplugged and plugged in the sata cables to drives and boot up the machine I almost lost the pool. It went from healthy to degradaded with 2 drives removed from the pool. I replaced one, but WD drive was getting kicked out of the pool. So I replaced it with new Toshiba P300 drive I got from warranty claim and same errors happended. The drive was kicked out of the pool as well:
I am just not sure what to do anymore. It doesn't look like hardware error anymore to me, at least when it comes to drives and sata cables. This was brand new Toshiba drive removed, with new sata cable. I don't think I can be that unlucky in terms of drives, from 2 separate vendors. This is what GUI is showing up:
Do you have any ideas how can i troubleshoot it and make my pool healthy again? I know I can't fix the unrecoverable error (I had to delete snapshots, also wanted to change whenthey are done and forgot about it, my mistake I know) but I want to prevent future errors. I am suspecting maybe MOBO has some problems with that drives? They are all connected to SATA ports on MOBO. I am thinking on buying HBA card and connecting the drives to it. Do you think it might help?
My mobo is: Asrock e3v5 ws
Processor: intel pentium g4560
I am pasting zpool status as well:
Warning: settings changed through the CLI are not written to
the configuration database and will be reset on reboot.
root@freenas:~ # zpool status -v\
?
pool: chmura
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: scrub repaired 0 in 0 days 01:57:51 with 8 errors on Sun Sep 20 04:16:22 2020
config:
NAME STATE READ WRITE CKSUM
chmura DEGRADED 0 0 15.0K
raidz2-0 DEGRADED 0 0 60.0K
867640655208291443 UNAVAIL 0 0 0 was /dev/gptid/00bb206d-da79-11ea-bd48-d050999ece98
gptid/900cbecd-4c3a-11ea-9c4f-d050999ece98 DEGRADED 0 0 0 too many errors
replacing-2 DEGRADED 0 0 1.69K
4969840580276665161 REMOVED 0 0 0 was /dev/ada0p2
gptid/5e6de3ca-f6e0-11ea-8d13-d050999ece98 ONLINE 0 0 0
8319921696860204576 REMOVED 0 0 0 was /dev/gptid/9f4e4fea-fabd-11ea-8d13-d050999ece98
gptid/6ba25256-beeb-11ea-92c2-d050999ece98 DEGRADED 0 0 0 too many errors
gptid/233769e6-54d2-11ea-be8d-d050999ece98 DEGRADED 0 0 0 too many errors
gptid/147d9872-a728-11ea-a173-d050999ece98 DEGRADED 0 0 0 too many errors
errors: Permanent errors have been detected in the following files:
<metadata>:<0x8b>
<metadata>:<0x95>
<metadata>:<0x398>
<metadata>:<0x9b>
<metadata>:<0xb0>
<metadata>:<0xb3>
chmura/iocage/jails/chmurka3/root@ioc_update_11.3-RELEASE-p6_2020-09-15_02-26-28:<0x0>
pool: freenas-boot
state: ONLINE
scan: scrub repaired 0 in 0 days 00:02:10 with 0 errors on Wed Sep 16 03:47:10 2020
config:
Can you please share your thoughts on this?