ZFS Noob
Contributor
- Joined
- Nov 27, 2013
- Messages
- 129
Now I need to figure out why. I'm running a server with 72G RAM, 4 SAS drives in a RAID10 style config, with an Intel 320 SSD under-provisioned as a log device.
When I set sync=disabled I get 14,394 IOPS on random writes, versus 50 with sync=standard. Reads are 1,117 vs 88. (This is using FIO which I'm new to, but it means I don't need to install a Windows VM.
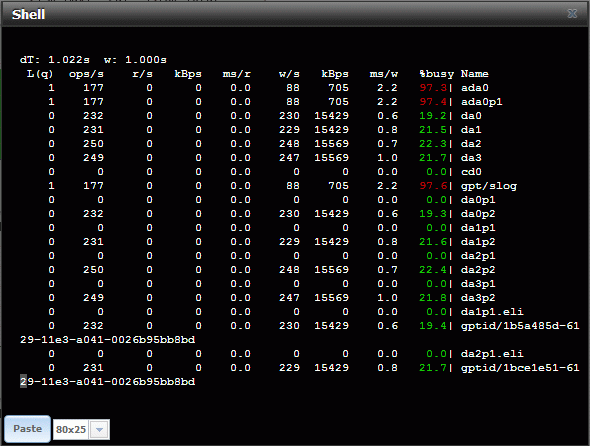
In trying to diagnose this I ran zpool iostat and got the following output:
Which shows that the 320 is doing ~ 101 writes per second (I think), versus the 8,000 that Intel advertises.
It's late and I'm new at this, but I'm not sure where to check first. Any suggestions?
When I set sync=disabled I get 14,394 IOPS on random writes, versus 50 with sync=standard. Reads are 1,117 vs 88. (This is using FIO which I'm new to, but it means I don't need to install a Windows VM.
In trying to diagnose this I ran zpool iostat and got the following output:
Code:
capacity operations bandwidth
pool alloc free read write read write
-------------------------------------- ----- ----- ----- ----- ----- -----
nas1mirror 215G 3.41T 0 250 0 7.14M
mirror 108G 1.71T 0 69 0 3.20M
gptid/1b5a485d-6129-11e3-a041-0026b95bb8bd - - 0 52
0 3.20M
gptid/1bce1e51-6129-11e3-a041-0026b95bb8bd - - 0 51
0 3.20M
mirror 108G 1.71T 0 79 0 3.15M
gptid/1c420e8a-6129-11e3-a041-0026b95bb8bd - - 0 54
0 3.16M
gptid/1cb736f5-6129-11e3-a041-0026b95bb8bd - - 0 54
0 3.16M
logs - - - - - -
gpt/slog 12.1M 1.97G 0 101 0 813K
-------------------------------------- ----- ----- ----- ----- ----- -----
It's late and I'm new at this, but I'm not sure where to check first. Any suggestions?