alieg
Dabbler
- Joined
- Jul 12, 2013
- Messages
- 44
So I'd been getting some SMART errors for one of my disks a while ago, I have mirrored disks & bittorrent sync to 2 PC's for important files, so I decided just to monitor it - nothing really happened for several months until last weekend when my 2nd HDD failed aSMART test.
I decided to replace both drives (approx 18 months old 2TB WD Greens) on Monday, but as soon as I replaced the first drive I got a SMART failure from the new disk, & have been continuing to get errors every time I reboot.
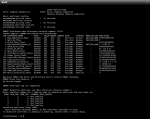
This message was generated by the smartd daemon running on:
host name: freenas
DNS domain: local
The following warning/error was logged by the smartd daemon:
Device: /dev/ada0, Failed SMART usage Attribute: 1 Raw_Read_Error_Rate.
I don't know if I can trust the results for a brand new drive, & I'm having trouble interpreting them,
if someone could at least point me in the right direction, that would be great :)
SMART Attributes Data Structure revision number: 12033
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0xc82f 000 200 051 Pre-fail Always FAILING_NOW 3298534883328
3 Spin_Up_Time 0xfd27 000 253 021 Pre-fail Always FAILING_NOW 0
4 Start_Stop_Count 0x6432 002 100 000 Old_age Always - 5497558138882
5 Reallocated_Sector_Ct 0xc833 000 200 140 Pre-fail Always FAILING_NOW 0 (1792 0)
7 Seek_Error_Rate 0xfd2e 000 253 000 Old_age Always - 9895604649984
9 Power_On_Hours 0x6432 081 100 000 Old_age Always - 81 (10 0 0)
10 Spin_Retry_Count 0xfd32 000 253 000 Old_age Always - 12094627905536
11 Calibration_Retry_Count 0xfd32 000 253 000 Old_age Always - 13194139533312
12 Power_Cycle_Count 0x6432 002 100 000 Old_age Always - 211106232532994
192 Power-Off_Retract_Count 0xc832 000 200 000 Old_age Always - 212205744160768
193 Load_Cycle_Count 0xc832 010 200 000 Old_age Always - 213305255788554
194 Temperature_Celsius 0x6e22 033 110 000 Old_age Always - 33 (196 0 0 0 0)
196 Reallocated_Event_Count 0xc832 000 200 000 Old_age Always - 0 (50432 0)
197 Current_Pending_Sector 0xc832 000 200 000 Old_age Always - 217703302299648
198 Offline_Uncorrectable 0xfd30 000 253 000 Old_age Offline - 218802813927424
199 UDMA_CRC_Error_Count 0xc832 000 200 000 Old_age Always - 219902325555200
200 Multi_Zone_Error_Rate 0xc808 000 200 000 Old_age Offline - 0
Warning! SMART ATA Error Log Structure error: invalid SMART checksum.
SMART Error Log Version: 0
No Errors Logged
Version: FreeNAS-9.2.1.5-RELEASE-x64 (80c1d35)
I decided to replace both drives (approx 18 months old 2TB WD Greens) on Monday, but as soon as I replaced the first drive I got a SMART failure from the new disk, & have been continuing to get errors every time I reboot.
This message was generated by the smartd daemon running on:
host name: freenas
DNS domain: local
The following warning/error was logged by the smartd daemon:
Device: /dev/ada0, Failed SMART usage Attribute: 1 Raw_Read_Error_Rate.
I don't know if I can trust the results for a brand new drive, & I'm having trouble interpreting them,
if someone could at least point me in the right direction, that would be great :)
SMART Attributes Data Structure revision number: 12033
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0xc82f 000 200 051 Pre-fail Always FAILING_NOW 3298534883328
3 Spin_Up_Time 0xfd27 000 253 021 Pre-fail Always FAILING_NOW 0
4 Start_Stop_Count 0x6432 002 100 000 Old_age Always - 5497558138882
5 Reallocated_Sector_Ct 0xc833 000 200 140 Pre-fail Always FAILING_NOW 0 (1792 0)
7 Seek_Error_Rate 0xfd2e 000 253 000 Old_age Always - 9895604649984
9 Power_On_Hours 0x6432 081 100 000 Old_age Always - 81 (10 0 0)
10 Spin_Retry_Count 0xfd32 000 253 000 Old_age Always - 12094627905536
11 Calibration_Retry_Count 0xfd32 000 253 000 Old_age Always - 13194139533312
12 Power_Cycle_Count 0x6432 002 100 000 Old_age Always - 211106232532994
192 Power-Off_Retract_Count 0xc832 000 200 000 Old_age Always - 212205744160768
193 Load_Cycle_Count 0xc832 010 200 000 Old_age Always - 213305255788554
194 Temperature_Celsius 0x6e22 033 110 000 Old_age Always - 33 (196 0 0 0 0)
196 Reallocated_Event_Count 0xc832 000 200 000 Old_age Always - 0 (50432 0)
197 Current_Pending_Sector 0xc832 000 200 000 Old_age Always - 217703302299648
198 Offline_Uncorrectable 0xfd30 000 253 000 Old_age Offline - 218802813927424
199 UDMA_CRC_Error_Count 0xc832 000 200 000 Old_age Always - 219902325555200
200 Multi_Zone_Error_Rate 0xc808 000 200 000 Old_age Offline - 0
Warning! SMART ATA Error Log Structure error: invalid SMART checksum.
SMART Error Log Version: 0
No Errors Logged
Version: FreeNAS-9.2.1.5-RELEASE-x64 (80c1d35)