Man this is a well researched thread with some very valuable information.
Maybe I can share some first hand experience. It turns out the best way to test the ECC capabilities of the X470D4U (I don't have the 10G variant but I recon this doesn't matter here) is if you have some faulty memory at hand.
I was 'lucky' enough to get sent 2 Kingston KSM26ED8/16ME modules which caused me massive headaches until I discovered that they are indeed both bad using memtest86. The headaches were frequent restarts of at least once every other day.
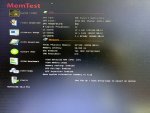
Once I got around to run memtest86 it turned out that each of the modules was generating 100s of correctable errors within one pass (round about 1,5 hours duration).
I then RMA'd the RAM modules and swapped them against modules that passed memtest86 and since then my stability issues are resolved.
My reasoning would be now that with such a high error rate the chances of getting an uncorrectable double bit flip error in a reasonable amount of time (let's say every other day) is not at all unlikely. If I recall correctly the correct system response to a double bit flip error if caught by ECC would be to throw a panic and initiate a restart. I don't have any direct proof, but based on my experience with the faulty RAM I would conclude that ECC is implemented (at least in parts) correctly in the X470D4U and the system will respond correctly when faced with an uncorrectable ECC error.
I can also confirm that none of the above, correctable or uncorrectable error, was ever manifested in the IPMI event log. So the answer
@Mastakilla received from ASRock, that reporting is not implemented on AM4, confirms the suspicion I had.
So far so good, I have one interesting tid bit to share though. I noticed that my console/dmesg contained frequent events from the Machine Check Architecture like so:
Code:
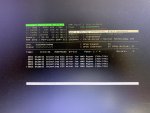
Oct 18 21:30:06 tempest MCA: Bank 16, Status 0xd42040000000011b
Oct 18 21:30:06 tempest MCA: Global Cap 0x0000000000000117, Status 0x0000000000000000
Oct 18 21:30:06 tempest MCA: Vendor "AuthenticAMD", ID 0x800f82, APIC ID 0
Oct 18 21:30:06 tempest MCA: CPU 0 COR OVER GCACHE LG RD error
Oct 18 21:30:06 tempest MCA: Address 0x4000000e89dfd40
Which indicates that some correctable read error in some cache occurred.
Likewise my restarts/crashes typically contained this last output in /data/crash:
Code:
MCA: Bank 0, Status 0xb4002800000c0135
MCA: Global Cap 0x0000000000000117, Status 0x0000000000000007
MCA: Vendor "AuthenticAMD", ID 0x800f82, APIC ID 10
MCA: CPU 8 UNCOR DCACHE L1 DRD error
MCA: Address 0x1000004dae13400
panic: Unrecoverable machine check exception
cpuid = 8
Saying that this time some uncorrectable error occurred.
Needless to say that all these have disappeared since I swapped the RAM.
It appears though that although the IPMI log is unable to show anything. FreeNAS is made aware of the fact that some ECC error has occurred via the MCA.
It is not ideal but in case these events (especially the correctable once) start to show up in the console or in the daily email from your FreeNAS box it might indicate that one of the RAM modules is starting to go bad.
Hope this helps someone. It cost me a lot of hair pulling and frustration so I thought I should share.