
S.co.tt
Cadet
- Joined
- Feb 27, 2016
- Messages
- 2
Hi all,
First I want to give a great thanks to aran kaspar on here for the awesome writeup on setting up an FC target. It worked perfectly and immediately.
The first thing I did was expose a 1TB file extent as a LUN to one of my VM servers (CentOS 6 / Xen), created an ext4 filesystem, & etc. and was able to read/write just fine. I ran a backup script copying a raw snapshot of all the VMs on the system to the LUN as a test. About 850GB in total.
All went well for the first ~65GB, then I started seeing kernel: Buffer I/O error on device sdc1 repeatedly on the initator (sdc was the devname of the LUN).
On the target (FreeNAS) ctladm dumpooa showed during the transfer, at any given time, one command taking a long time to complete (the remainder were on the order of 0-100ms) -- so long that it was causing the HBA drivers on the initiator to time out. Increasing the timeout didn't help, because at some point a command would eventually take more than the timeout to complete (I went up to 2 mins at any rate).
I thought I'd narrowed it down to a bad disk (which didn't show as bad from smartd, but it was absurdly slow and the whole array was waiting on it). After the disk was replaced I ran the same backup script again. It was running great, and nothing in the command queue was waiting longer than 2-3 seconds in absolute worst cases. Most wait times were in the 0-15ms range.
At this point, in an act of hubris, I prematurely wrote up a blog post on the "fix" as the backup was progressing into the hundreds of GBs. That link has a lot more background.
About 750GB into the 850GB backup (which honestly was just a dd for a snapshot of each raw logical volume), the following errors showed up on the initiator:
The kernel: Buffer I/O error on device sdc1, logical block error was repeated hundreds of times, with the rest of the above errors popping up intermittently. I believe this is because the FreeNAS box slowed to a crawl (and eventually crashed).
On the FreeNAS server all that was held in /var/log/messages surrounding the time period was:
Not much help, because as you can see it logged a normal smartd error at 13:30 (about firmware being out of date on a drive), a non-fatal error at 19:22, and a boot up at 21:12. However, I believe that the entire storage subsystem crapped out because at the time I happened to have the console open on an IP KVM session on another monitor, and at about 20:52 I saw this pop up:
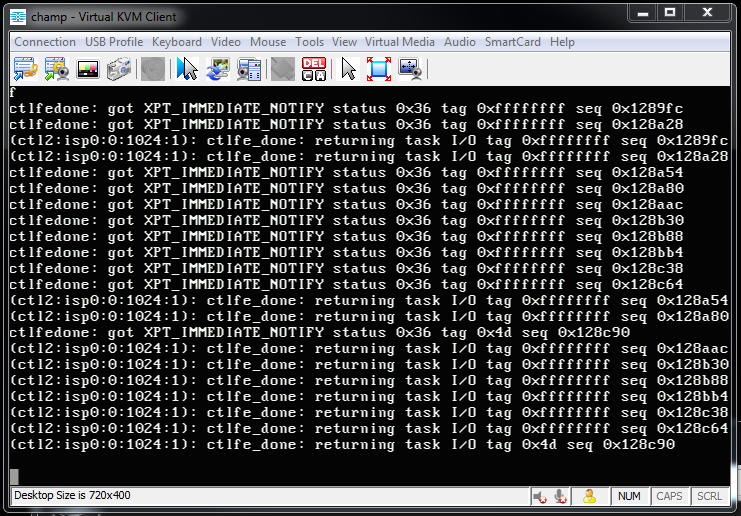
These were the same errors I'd been getting in the first place that I chalked up to the array hanging on a bad drive. I immediately went to do a ctladm dumpooa, but my SSH session was frozen as was the console. I thought the system was completely hung -- no more messages at the console and no visible disk activity -- but at about 21:04 (12 mins later):
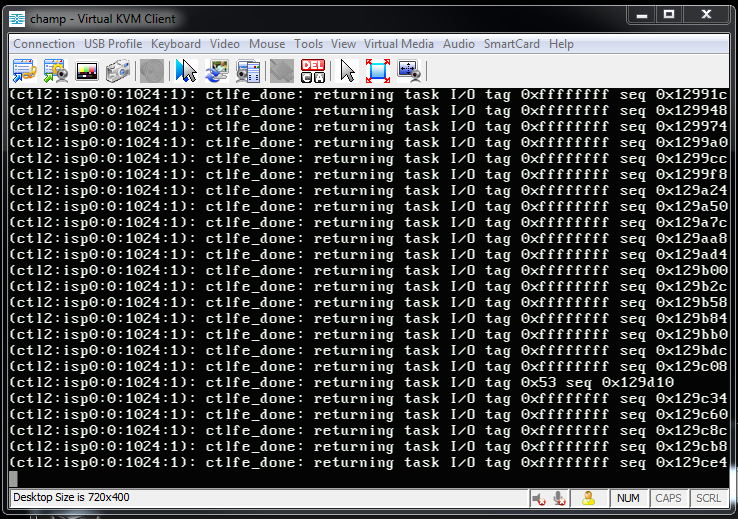
Then nothing for about 10 mins, and then I heard the fans throttle up because the box was POSTing. Looks like a kernel panic reboot or .. something. IPMI shows no problems at the hardware level.
It booted back up just fine like nothing happened. I'm able to read and write to the LUN again (with a issue_lip and scan to the HBA), and as I write this I've read about 200GB from the LUN so far (I'm kind of afraid to re-do the write test again).
But I could really use some guidance here. I had a similar setup on Solaris w/ZFS for a few years, but I'm a FreeNAS / FreeBSD noob.
I'd love to dump more logs, and would be happy to throw you guys more info. I just don't know where to start digging around that might be useful, so please let me know what you'd like to see if you have any ideas.
FWIW I really don't think it's hardware or driver related (aside from perhaps the HBA's driver). I've had the FreeNAS box up and running for about 2 months now and transferred about 15TB onto it with no problems (other than slow 10Gb CIFS performance, but that's a sad story for another day). It's been rock solid solid, as had all the same FC hardware been in its previous incarnation.
But it's weird that it could take a transfer of ~750GB without a hiccup and then suddenly fail, right?
Here's the FreeNAS hardware, BTW:
Oh, and apologies for the wall of text and thanks in advance!
First I want to give a great thanks to aran kaspar on here for the awesome writeup on setting up an FC target. It worked perfectly and immediately.
The first thing I did was expose a 1TB file extent as a LUN to one of my VM servers (CentOS 6 / Xen), created an ext4 filesystem, & etc. and was able to read/write just fine. I ran a backup script copying a raw snapshot of all the VMs on the system to the LUN as a test. About 850GB in total.
All went well for the first ~65GB, then I started seeing kernel: Buffer I/O error on device sdc1 repeatedly on the initator (sdc was the devname of the LUN).
On the target (FreeNAS) ctladm dumpooa showed during the transfer, at any given time, one command taking a long time to complete (the remainder were on the order of 0-100ms) -- so long that it was causing the HBA drivers on the initiator to time out. Increasing the timeout didn't help, because at some point a command would eventually take more than the timeout to complete (I went up to 2 mins at any rate).
I thought I'd narrowed it down to a bad disk (which didn't show as bad from smartd, but it was absurdly slow and the whole array was waiting on it). After the disk was replaced I ran the same backup script again. It was running great, and nothing in the command queue was waiting longer than 2-3 seconds in absolute worst cases. Most wait times were in the 0-15ms range.
At this point, in an act of hubris, I prematurely wrote up a blog post on the "fix" as the backup was progressing into the hundreds of GBs. That link has a lot more background.
About 750GB into the 850GB backup (which honestly was just a dd for a snapshot of each raw logical volume), the following errors showed up on the initiator:
Feb 28 20:50:42 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 20:52:43 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 20:54:44 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 20:56:45 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 20:58:46 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 21:00:47 hp-vm02 kernel: lpfc 0000:07:00.0: 1:(0):0713 SCSI layer issued Device Reset (0, 1) return x2002
Feb 28 21:00:47 hp-vm02 kernel: sd 1:0:0:1: [sdc] Unhandled error code
Feb 28 21:00:47 hp-vm02 kernel: sd 1:0:0:1: [sdc] Result: hostbyte=DID_REQUEUE driverbyte=DRIVER_OK
Feb 28 21:00:47 hp-vm02 kernel: sd 1:0:0:1: [sdc] CDB: Write(10): 2a 00 55 57 20 3f 00 02 00 00
Feb 28 21:00:47 hp-vm02 kernel: end_request: I/O error, dev sdc, sector 1431773247
Feb 28 21:00:47 hp-vm02 kernel: Buffer I/O error on device sdc1, logical block 178971648
Feb 28 21:00:47 hp-vm02 kernel: Buffer I/O error on device sdc1, logical block 178971649
The kernel: Buffer I/O error on device sdc1, logical block error was repeated hundreds of times, with the rest of the above errors popping up intermittently. I believe this is because the FreeNAS box slowed to a crawl (and eventually crashed).
On the FreeNAS server all that was held in /var/log/messages surrounding the time period was:
Feb 28 13:30:32 champ smartd[52957]: http://knowledge.seagate.com/articles/en_US/FAQ/223651en
Feb 28 19:22:34 champ ctlfedone: got XPT_IMMEDIATE_NOTIFY status 0x36 tag 0xffffffff seq 0xffffffff
Feb 28 19:22:34 champ (ctl0:isp0:0:-1:-1): ctlfe_done: returning task I/O tag 0xffffffff seq 0xffffffff
Feb 28 21:12:33 champ syslog-ng[3083]: syslog-ng starting up; version='3.5.6'
Not much help, because as you can see it logged a normal smartd error at 13:30 (about firmware being out of date on a drive), a non-fatal error at 19:22, and a boot up at 21:12. However, I believe that the entire storage subsystem crapped out because at the time I happened to have the console open on an IP KVM session on another monitor, and at about 20:52 I saw this pop up:
These were the same errors I'd been getting in the first place that I chalked up to the array hanging on a bad drive. I immediately went to do a ctladm dumpooa, but my SSH session was frozen as was the console. I thought the system was completely hung -- no more messages at the console and no visible disk activity -- but at about 21:04 (12 mins later):
Then nothing for about 10 mins, and then I heard the fans throttle up because the box was POSTing. Looks like a kernel panic reboot or .. something. IPMI shows no problems at the hardware level.
It booted back up just fine like nothing happened. I'm able to read and write to the LUN again (with a issue_lip and scan to the HBA), and as I write this I've read about 200GB from the LUN so far (I'm kind of afraid to re-do the write test again).
But I could really use some guidance here. I had a similar setup on Solaris w/ZFS for a few years, but I'm a FreeNAS / FreeBSD noob.
I'd love to dump more logs, and would be happy to throw you guys more info. I just don't know where to start digging around that might be useful, so please let me know what you'd like to see if you have any ideas.
FWIW I really don't think it's hardware or driver related (aside from perhaps the HBA's driver). I've had the FreeNAS box up and running for about 2 months now and transferred about 15TB onto it with no problems (other than slow 10Gb CIFS performance, but that's a sad story for another day). It's been rock solid solid, as had all the same FC hardware been in its previous incarnation.
But it's weird that it could take a transfer of ~750GB without a hiccup and then suddenly fail, right?
Here's the FreeNAS hardware, BTW:
- That giant Supermicro 36 x 3.5" case
- X8DTH-iF mobo
- 1 x X5687 3.6Ghz QC
- 96GB PC3-12800R
- 5x PERC H310 (flashed with LSI fw to IT mode)
- Pool01: 10 x 3TB RAIDZ2 + 10 x 3TB RAIDZ2 (this is the pool in question)
- Pool02: 3 x 1TB mirror
- Intel 10Gb XF SR
- QLE2460 4Gb HBA (flashed to IT mode) to Brocade 200E switch
Oh, and apologies for the wall of text and thanks in advance!