isopropyl
Contributor
- Joined
- Jan 29, 2022
- Messages
- 159
Was moving my server to a rack, had taken all the drives out before moving, was cautious with it, and when booting online everything was fine for a few days.
Then suddenly I got an email while at work, that 2 drives were unavailable and 1 was degraded. I went on and looked and didn't know what to do.
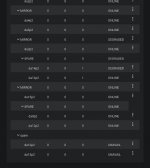
Also it's weird that the two unavailable drives are both spares? But also I see at the top of the picture it shows da14p2 which is listed under "SPARE" which is listed under "MIRROR". So I'm not sure if I'm reading it wrong. I'm very confused.
I don't think it's the drives.
3 drives at once? Can't be. They were bought at different times, and bought used (From a seller which I've had zero issues from all these other like 18 drives from).
Unless it's saying that one drive failed (degraded) and the other 2 are unavailable because it resilvered to them? But why are 2 unavailable then? Just very confused.
So a few hours later I was heading home, I could still access the server.
Then suddenly 10min later between checking it, and getting home. I walk into my room, and the server is off. I pulled it out and the HBA pulled out a little because I didn't have it screwed down and the back of the server slides out from the front because it has rear backplane. So the wires pulled a bit.
I put it all back together, and reseated wires and stuff and it works fine and booted.
I reran a scrub, and the same exact drive shows degraded, and 2 unavailable.
I am not very familiar with diag and not sure where to start, what might be the issue.
I had ran smart tests on the 3 drives and I think they all seemed to pass?
It's a TrueNAS Core, and a Supermicro server with a LSI HBA in IT Mode for reference.
Then suddenly I got an email while at work, that 2 drives were unavailable and 1 was degraded. I went on and looked and didn't know what to do.
Also it's weird that the two unavailable drives are both spares? But also I see at the top of the picture it shows da14p2 which is listed under "SPARE" which is listed under "MIRROR". So I'm not sure if I'm reading it wrong. I'm very confused.
I don't think it's the drives.
3 drives at once? Can't be. They were bought at different times, and bought used (From a seller which I've had zero issues from all these other like 18 drives from).
Unless it's saying that one drive failed (degraded) and the other 2 are unavailable because it resilvered to them? But why are 2 unavailable then? Just very confused.
So a few hours later I was heading home, I could still access the server.
Then suddenly 10min later between checking it, and getting home. I walk into my room, and the server is off. I pulled it out and the HBA pulled out a little because I didn't have it screwed down and the back of the server slides out from the front because it has rear backplane. So the wires pulled a bit.
I put it all back together, and reseated wires and stuff and it works fine and booted.
I reran a scrub, and the same exact drive shows degraded, and 2 unavailable.
I am not very familiar with diag and not sure where to start, what might be the issue.
I had ran smart tests on the 3 drives and I think they all seemed to pass?
It's a TrueNAS Core, and a Supermicro server with a LSI HBA in IT Mode for reference.
Code:
# cat /var/log/messagesSep 21 00:00:00 hinata newsyslog[7010]: logfile turned over due to size>200KSep 21 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, r eloading configuration;Sep 21 00:00:00 hinata syslog-ng[1663]: Configuration reload finished;Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): READ(16). CDB: 88 00 00 00 00 01 79 5 a 75 d0 00 00 08 00 00 00 Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): CAM status: SCSI Status ErrorSep 21 00:08:10 hinata (da11:mpr0:0:26:0): SCSI status: Check ConditionSep 21 00:08:10 hinata (da11:mpr0:0:26:0): SCSI sense: ABORTED COMMAND asc:4b,3 (ACK/NAK timeout) Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): Command Specific Info: 0 Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): Descriptor 0x80: f5 51 Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): Descriptor 0x81: 00 00 00 00 00 00Sep 21 00:08:10 hinata (da11:mpr0:0:26:0): Retrying command (per sense data)Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): READ(10). CDB: 28 00 a3 90 c8 d8 00 08 00 00 Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): CAM status: SCSI Status ErrorSep 21 00:21:44 hinata (da7:mpr0:0:22:0): SCSI status: Check ConditionSep 21 00:21:44 hinata (da7:mpr0:0:22:0): SCSI sense: ABORTED COMMAND asc:4b,4 ( NAK received) Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): Command Specific Info: 0 Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): Descriptor 0x80: f5 50 Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 00:21:44 hinata (da7:mpr0:0:22:0): Retrying command (per sense data) Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): READ(16). CDB: 88 00 00 00 00 01 2c be bd 10 00 00 08 00 00 00 Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): CAM status: SCSI Status Error Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): SCSI status: Check Condition Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): SCSI sense: ABORTED COMMAND asc:4b,4(NAK received) Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): Command Specific Info: 0 Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): Descriptor 0x80: f5 50 Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 00:31:52 hinata (da10:mpr0:0:25:0): Retrying command (per sense data) Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): READ(10). CDB: 28 00 a1 0b 8b c0 00 01 00 00 Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): CAM status: SCSI Status Error Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): SCSI status: Check Condition Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): Command Specific Info: 0 Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): Descriptor 0x80: f5 50 Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 00:35:48 hinata (da8:mpr0:0:23:0): Retrying command (per sense data) Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): READ(16). CDB: 88 00 00 00 00 01 01 a1 2b 98 00 00 08 00 00 00 Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): CAM status: SCSI Status Error Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): SCSI status: Check Condition Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): Command Specific Info: 0 Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): Descriptor 0x80: f5 50 Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 00:39:05 hinata (da8:mpr0:0:23:0): Retrying command (per sense data) Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): READ(10). CDB: 28 00 4a c5 96 60 00 08 00 00 Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): CAM status: SCSI Status Error Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): SCSI status: Check Condition Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): SCSI sense: ABORTED COMMAND asc:4b,3 (ACK/NAK timeout) Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): Command Specific Info: 0 Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): Descriptor 0x80: f5 51 Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 01:36:32 hinata (da0:mpr0:0:15:0): Retrying command (per sense data) Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): READ(10). CDB: 28 00 97 a8 fc d0 00 08 00 00 Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): CAM status: SCSI Status Error Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): SCSI status: Check Condition Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): SCSI sense: ABORTED COMMAND asc:4b,4(NAK received) Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): Command Specific Info: 0 Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): Descriptor 0x80: f5 50 Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 01:43:43 hinata (da10:mpr0:0:25:0): Retrying command (per sense data) Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): READ(16). CDB: 88 00 00 00 00 01 66 f8 f8 c0 00 00 08 00 00 00 Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): CAM status: SCSI Status Error Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): SCSI status: Check Condition Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): Command Specific Info: 0 Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): Descriptor 0x80: f5 50 Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 02:50:46 hinata (da7:mpr0:0:22:0): Retrying command (per sense data) Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): READ(16). CDB: 88 00 00 00 00 01 2c fd 3a 80 00 00 08 00 00 00 Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): CAM status: SCSI Status Error Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): SCSI status: Check Condition Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): Command Specific Info: 0 Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): Descriptor 0x80: f5 50 Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 02:58:49 hinata (da8:mpr0:0:23:0): Retrying command (per sense data) Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): READ(10). CDB: 28 00 82 e0 17 78 00 08 00 00 Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): CAM status: SCSI Status Error Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): SCSI status: Check Condition Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): SCSI sense: ABORTED COMMAND asc:4b,4(NAK received) Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): Command Specific Info: 0 Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): Descriptor 0x80: f5 50 Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 03:16:12 hinata (da11:mpr0:0:26:0): Retrying command (per sense data) Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): READ(16). CDB: 88 00 00 00 00 01 5d c1 b2 48 00 00 08 00 00 00 Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): CAM status: SCSI Status Error Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): SCSI status: Check Condition Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): Command Specific Info: 0 Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): Descriptor 0x80: f5 50 Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 03:26:37 hinata (da7:mpr0:0:22:0): Retrying command (per sense data) Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): READ(10). CDB: 28 00 13 cc dc c8 00 08 00 00 Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): CAM status: SCSI Status Error Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): SCSI status: Check Condition Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): Command Specific Info: 0 Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): Descriptor 0x80: f5 50 Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 04:15:57 hinata (da6:mpr0:0:21:0): Retrying command (per sense data) Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 67 f8 bf 30 00 00 08 00 00 00 Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): CAM status: SCSI Status Error Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): SCSI status: Check Condition Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): Command Specific Info: 0 Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): Descriptor 0x80: f5 50 Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 04:30:42 hinata (da2:mpr0:0:17:0): Retrying command (per sense data) Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 0c 1c 7f a8 00 00 08 00 00 00 Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): CAM status: SCSI Status Error Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): SCSI status: Check Condition Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): Command Specific Info: 0 Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): Descriptor 0x80: f5 50 Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 05:16:36 hinata (da2:mpr0:0:17:0): Retrying command (per sense data) Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): READ(16). CDB: 88 00 00 00 00 01 23 d4 74 40 00 00 08 00 00 00 Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): CAM status: SCSI Status Error Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): SCSI status: Check Condition Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): Command Specific Info: 0 Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): Descriptor 0x80: f5 50 Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 05:23:16 hinata (da1:mpr0:0:16:0): Retrying command (per sense data) Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): READ(16). CDB: 88 00 00 00 00 01 70 dd 6f 38 00 00 08 00 00 00 Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): CAM status: SCSI Status Error Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): SCSI status: Check Condition Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): Command Specific Info: 0 Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): Descriptor 0x80: f5 50 Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 05:40:37 hinata (da2:mpr0:0:17:0): Retrying command (per sense data) Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): READ(16). CDB: 88 00 00 00 00 01 a0 1e 91 98 00 00 08 00 00 00 Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): CAM status: SCSI Status Error Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): SCSI status: Check Condition Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): SCSI sense: ABORTED COMMAND asc:4b,4(NAK received) Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): Command Specific Info: 0 Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): Descriptor 0x80: f5 50 Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 05:56:20 hinata (da10:mpr0:0:25:0): Retrying command (per sense data) Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): READ(10). CDB: 28 00 d2 ae 6c 60 00 00 a0 00 Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): CAM status: SCSI Status Error Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): SCSI status: Check Condition Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): Command Specific Info: 0 Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): Descriptor 0x80: f5 50 Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 06:25:12 hinata (da5:mpr0:0:20:0): Retrying command (per sense data) Sep 21 07:35:44 hinata 1 2022-09-21T11:35:44.179287+00:00 hinata.lan ctld 14350- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 21 07:35:45 hinata 1 2022-09-21T11:35:45.182762+00:00 hinata.lan ctld 14351- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 21 07:35:46 hinata 1 2022-09-21T11:35:46.703310+00:00 hinata.lan ctld 14352- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): READ(10). CDB: 28 00 76 37 f5 b0 00 01 00 00 Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): CAM status: SCSI Status Error Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): SCSI status: Check Condition Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): Command Specific Info: 0 Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): Descriptor 0x80: f5 50 Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 21 08:36:52 hinata (da7:mpr0:0:22:0): Retrying command (per sense data) Sep 22 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 22 00:00:00 hinata syslog-ng[1663]: Configuration reload finished; Sep 23 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 23 00:00:00 hinata syslog-ng[1663]: Configuration reload finished; Sep 24 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 24 00:00:00 hinata syslog-ng[1663]: Configuration reload finished; Sep 25 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 25 00:00:00 hinata syslog-ng[1663]: Configuration reload finished; Sep 25 11:53:26 hinata WARNING: 10.0.10.10 (andromeda): no ping reply (NOP-Out)after 5 seconds; dropping connection Sep 25 11:54:25 hinata WARNING[1663]: Last message '10.0.10.10 (andromed' repeated 1 times, suppressed by syslog-ng on hinata.lan Sep 25 12:18:28 hinata 1 2022-09-25T16:18:28.400386+00:00 hinata.lan ctld 7877 - - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 12:18:29 hinata 1 2022-09-25T16:18:29.403051+00:00 hinata.lan ctld 7878 - - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 12:18:30 hinata 1 2022-09-25T16:18:30.928443+00:00 hinata.lan ctld 7879 - - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 13:59:26 hinata WARNING: 10.0.10.10 (andromeda): no ping reply (NOP-Out)after 5 seconds; dropping connection Sep 25 14:00:25 hinata WARNING[1663]: Last message '10.0.10.10 (andromed' repeated 1 times, suppressed by syslog-ng on hinata.lan Sep 25 14:42:19 hinata 1 2022-09-25T18:42:19.208664+00:00 hinata.lan ctld 10039- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 14:42:20 hinata 1 2022-09-25T18:42:20.216649+00:00 hinata.lan ctld 10040- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 14:42:20 hinata 1 2022-09-25T18:42:20.222651+00:00 hinata.lan ctld 10041- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 14:47:11 hinata WARNING: 10.0.10.10 (andromeda): no ping reply (NOP-Out)after 5 seconds; dropping connection Sep 25 14:48:12 hinata WARNING[1663]: Last message '10.0.10.10 (andromed' repeated 1 times, suppressed by syslog-ng on hinata.lan Sep 25 16:37:16 hinata 1 2022-09-25T20:37:16.641270+00:00 hinata.lan ctld 11771- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 16:37:17 hinata 1 2022-09-25T20:37:17.629774+00:00 hinata.lan ctld 11772- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 16:37:18 hinata 1 2022-09-25T20:37:18.650490+00:00 hinata.lan ctld 11773- - 10.0.10.10: invalid target name "andromeda"; should start with either "iqn.", "eui.", or "naa." Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): READ(10). CDB: 28 00 32 93 b8 d8 00 01 00 00 Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): CAM status: SCSI Status Error Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): SCSI status: Check Condition Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): SCSI sense: ABORTED COMMAND asc:4b,4 (NAK received) Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): Command Specific Info: 0 Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): Descriptor 0x80: f5 50 Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): Descriptor 0x81: 00 00 00 00 00 00 Sep 25 16:51:07 hinata (da0:mpr0:0:15:0): Retrying command (per sense data) Sep 26 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 26 00:00:00 hinata syslog-ng[1663]: Configuration reload finished; Sep 26 03:14:46 hinata 1 2022-09-26T03:14:46.550382-04:00 hinata.lan smartd 2072 - - Device: /dev/da14, not capable of Long Self-Test Sep 26 03:14:46 hinata 1 2022-09-26T03:14:46.556033-04:00 hinata.lan smartd 2072 - - Device: /dev/da15, not capable of Long Self-Test Sep 26 03:14:46 hinata 1 2022-09-26T03:14:46.560808-04:00 hinata.lan smartd 2072 - - Device: /dev/da9, not capable of Long Self-Test Sep 26 03:14:46 hinata 1 2022-09-26T03:14:46.565485-04:00 hinata.lan smartd 2072 - - Device: /dev/da13, not capable of Long Self-Test Sep 26 03:14:46 hinata 1 2022-09-26T03:14:46.570851-04:00 hinata.lan smartd 2072 - - Device: /dev/da12, not capable of Long Self-Test Sep 27 00:00:00 hinata syslog-ng[1663]: Configuration reload request received, reloading configuration; Sep 27 00:00:00 hinata syslog-ng[1663]: Configuration reload finished;