xness
Dabbler
- Joined
- Jun 3, 2022
- Messages
- 30
Hello TrueNAS community,
I recently fell into the beautiful world of ZFS+TrueNAS and just built the first appliance.
I benchmarked quite a bit with dd and bonnie++ to get an idea what the limits of the HBA controllers simultaneous write-performance was – but quickly figured they wouldn't be representative of a real-world scenario. So I created a 4K block-size iSCSI share, hooked it up to a 10GbE server and formatted it with NTFS.
Now I know ZFS is a Copy-On-Write system, but I expected the submitting of the writes to be less impactful and I'm not sure the extreme performance variation I'm experiencing is what's to be expected. It sometimes climbs to 1 GB/s and the drops all the way to 0 Byte/s for a couple of seconds. I would feel much better, if it just averaged out in-between.
I recorded a quick video of it below.
Anyways – here are my specs configuration. I know 10 disks is the absolute maximum any given pool should have and the resilvering time for a pool of this size is likely not ideal.
General hardware:
Happy for any help. If I missed some information that's required, please let me know.
I recently fell into the beautiful world of ZFS+TrueNAS and just built the first appliance.
I benchmarked quite a bit with dd and bonnie++ to get an idea what the limits of the HBA controllers simultaneous write-performance was – but quickly figured they wouldn't be representative of a real-world scenario. So I created a 4K block-size iSCSI share, hooked it up to a 10GbE server and formatted it with NTFS.
Now I know ZFS is a Copy-On-Write system, but I expected the submitting of the writes to be less impactful and I'm not sure the extreme performance variation I'm experiencing is what's to be expected. It sometimes climbs to 1 GB/s and the drops all the way to 0 Byte/s for a couple of seconds. I would feel much better, if it just averaged out in-between.
I recorded a quick video of it below.
Anyways – here are my specs configuration. I know 10 disks is the absolute maximum any given pool should have and the resilvering time for a pool of this size is likely not ideal.
General hardware:
- Motherboard: Supermicro X11SPI-TF
- Processor: Intel® Xeon® Silver 4110 Processor
- RAM: 96GB DDR4 (6x 16 GB DDR4 ECC 2933 MHz PC4-23400 SAMSUNG)
- Network card: On-board 10GbE (iperf3 shows 8Gbps throughput)
- Controller: LSI SAS9207-8i 2x SFF-8087 6G SAS PCIe x8 3.0 HBA
- Boot Drives: 2x 450GB SAMSUNG MZ7L3480 (via SATA)
- Pool: 10x 18TB WDC WUH721818AL (raidz2)
Code:
root@lilith[~]# zpool status -v
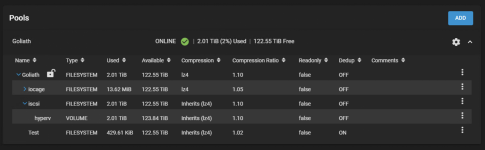
pool: Goliath
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
Goliath ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/7a492ffe-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a57523c-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a4cccdb-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a5554d2-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a501918-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a852e97-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a4f10b4-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a1ba28a-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a52cf0d-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
gptid/7a4b4df4-d841-11ec-92b7-3cecef0f0024 ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:04 with 0 errors on Wed Jun 1 03:45:04 2022
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
errors: No known data errorsHappy for any help. If I missed some information that's required, please let me know.