I'm experiencing a very disturbing problem with my FreeNAS rig, which has never occurred before. I'm not an expert, but I am seeking help about how to proceed.
Allow me to describe the situation. I set up this system 3 or 4 years ago - AsRock Rack C2550D4I 16GB ECC dimms, FreeNAS 11.1 U7 on 32GB USB Flash, and a couple 4TB WD Red HDDs organized as an 8TB pool without redundancy. I have never in that time had any critical errors or hardware faults. I always kept it updated, had it on a UPS battery backup, and it ran like champ, clocking 3 or 4 months uptime between fairly regular updates I would perform, scrubbing the volume every 35 days, and never producing any checksum mismatches. I use it for my own personal file storage, over SMB, and most of the time system load was about zero - extremely light usage.
So, I was highly distressed when I logged into the HTTP webclient and saw the flashing red light indicating a critical error, and that apart from the critical warning, the actual web interface was unresponsive (Stuck at "Loading...")(see screenshot). After re-booting the system, I found that many of my reporting databases had been degraded. (see screenshot). None of my other files were active at the time this occurred, so they're probably not affected.
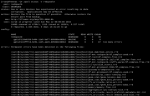
I saw that one of my drives had failed during a recently initiated automatic scrub. It was about 20% through the scrub, which resumed after reboot.
Each time I executed
My basic concerns can be summarized:
Allow me to describe the situation. I set up this system 3 or 4 years ago - AsRock Rack C2550D4I 16GB ECC dimms, FreeNAS 11.1 U7 on 32GB USB Flash, and a couple 4TB WD Red HDDs organized as an 8TB pool without redundancy. I have never in that time had any critical errors or hardware faults. I always kept it updated, had it on a UPS battery backup, and it ran like champ, clocking 3 or 4 months uptime between fairly regular updates I would perform, scrubbing the volume every 35 days, and never producing any checksum mismatches. I use it for my own personal file storage, over SMB, and most of the time system load was about zero - extremely light usage.
So, I was highly distressed when I logged into the HTTP webclient and saw the flashing red light indicating a critical error, and that apart from the critical warning, the actual web interface was unresponsive (Stuck at "Loading...")(see screenshot). After re-booting the system, I found that many of my reporting databases had been degraded. (see screenshot). None of my other files were active at the time this occurred, so they're probably not affected.
I saw that one of my drives had failed during a recently initiated automatic scrub. It was about 20% through the scrub, which resumed after reboot.
Each time I executed
zpool status -v I noticed that the checksum errors (97 in this screenshot) continued to increase, although the actual number of files affected remained the same. It made me nervous that the checksum error count kept rising, because I know that FreeNAS seems to update those reporting databases incessantly, so I just powered down the system. Now I'm not really sure what to do.My basic concerns can be summarized:
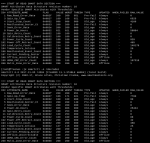
- is the HDD actually in failure or pre-failure and in need of replacement? (SMART readouts in screenshot)
- how do I get the system running normally again?
- if the .rrd files, which had been appended to for years, just failed in this one moment in time to be written to, wouldn't that leave them mostly intact (perhaps recoverable even)?
Attachments
Last edited: