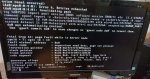
The system reports a critical alert,
CRITICAL: July 22, 2019, 11:05 a.m. - The volume VM-Datastore state is DEGRADED: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state.
I am trying to work out if the disk is as fault and, if so, which disk it is.
Background:
I've configured the Freenas 111-U7 as an iSCI datastore for a separate VMware machine. There are three datasets, two of the three containing VMs and the third as a backup (I'm working on this - hence the weird setup of a backup located here). This backup dataset (VM-Backup) had filled up completely, although now I've deleted some files now.

Running zpool status shows,
gptid/f8b9d75d-aecb-11e8-8fb0-ac1f6b2542fe
as the faulted drive

Using glabel status I cannot then find the drive listed (i.e., I'm missing "1" above):

I don't follow, why both ada4 and da1 appear twice - or am I reading something wrong?
For clarity this is the GUI:

Since I can identify da1, da2 and da3 it seems da0 is potentially at fault. However is passes SMART.
The recommendations seem to be to keep lots of free space on iSCI drives (maxing at say 60%). Since I've filled one datapool is this the root cause rather than a physical drive problem?
Any help on how to progress would be really appreciated!
CRITICAL: July 22, 2019, 11:05 a.m. - The volume VM-Datastore state is DEGRADED: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state.
I am trying to work out if the disk is as fault and, if so, which disk it is.
Background:
I've configured the Freenas 111-U7 as an iSCI datastore for a separate VMware machine. There are three datasets, two of the three containing VMs and the third as a backup (I'm working on this - hence the weird setup of a backup located here). This backup dataset (VM-Backup) had filled up completely, although now I've deleted some files now.
Running zpool status shows,
gptid/f8b9d75d-aecb-11e8-8fb0-ac1f6b2542fe
as the faulted drive
Using glabel status I cannot then find the drive listed (i.e., I'm missing "1" above):
I don't follow, why both ada4 and da1 appear twice - or am I reading something wrong?
For clarity this is the GUI:
Since I can identify da1, da2 and da3 it seems da0 is potentially at fault. However is passes SMART.
The recommendations seem to be to keep lots of free space on iSCI drives (maxing at say 60%). Since I've filled one datapool is this the root cause rather than a physical drive problem?
Any help on how to progress would be really appreciated!